ドメインロジックとSQL
以下の文章は、Martin Fowler による Domain Logic and SQLの日本語訳である。
データベース指向ソフトウェア開発者とメモリ上(in-memory)アプリケーションソフトウェア開発者との間のギャップは、ここ数十年、徐々に広がってきている。このギャップが原因で、データベースの機能(SQLやストアドプロシージャ)をどのように扱えばよいのかという議論が数多く巻き起こっている。ここでは、ビジネスロジックを SQL に置くべきか、それともメモリ上のコードに置くべきかといった問題について、主にパフォーマンスと更新性の観点から考察を行う。考察には簡単な例を使うが、SQL クエリはしっかりとしたもの(rich SQL queries)を用いるので悪しからず。
エンタープライズアプリケーション(訳注:以下、EA)構築に関する本(私の近著『P of EAA』など)を読むと、ロジックが、様々な個所で、複数のレイヤに分割されていることに気付くと思う。著者によってレイヤの分け方は違うが、よくあるのはドメインロジック(ビジネスルール)とデータソースロジック(データをどこから取得するか)との分離である。EAのデータはだいたい RDB に保存してあるため、このレイヤの分け方はビジネスロジックを RDB から離すための分け方だと言える。
アプリケーション開発者の多くは(特に私のような超 OO 開発者は)RDB のことを裏側に隠しておくのにちょうどいいストレージ装置だと思いがちだ。フレームワークというものもあるが、これだって、アプリケーション開発者は SQL の複雑さを考える必要なんかありませんよーとしつこい。
SQL は、今では単にデータをアップデートしたり、検索したりするためだけのものではなくなっている。SQL クエリを使えば様々なタスクを処理することができるのだ。アプリケーション開発者がSQLを使わないのは、強力なツールを排除しているのに等しい。
ここでは、リッチな SQL クエリを使うことの良い点、悪い点を深く掘り下げていく。リッチな SQL クエリにはドメインロジックが含まれることもある。そうだ、言っておかねばならないことがある。私はこの議題にオブジェクト指向のバイアスをかける。とはいえ、私は反対側の人間だったこともあるわけだが(以前のクライアントに OO エキスパートグループがあり、彼らに会社を追い出されたことがある。私が「データモデラー」だったからだ)。
複雑なクエリ(Complex Queries)
すべての RDB は、標準的な問い合わせ言語である SQL をサポートしている。RDB が成功し拡大し得たのは、基本的にこのSQLのおかげだと私は思っている。データベースとやり取りをする標準的な方法がほぼベンダー非依存で提供されたことで RDB は成長できた。だがこれにより、オブジェクト指向的な課題は先送りされることとなる。
SQL には多くの長所があるが、中でもデータベースへの問い合わせは非常にパワフルだ。これを使えばわずか数行の SQL コードで大容量のデータにフィルタをかけたり、サマリを行ったりすることが出来る。ドメインロジックを組み込むことも出来るが、「EAアーキテクチャはレイヤで構成される」という基本原則には反することになる。
簡単な例を用いながら詳しくみていこう。図1にあるようなデータモデルから始める。私たちの会社がスペシャルディスカウントを行うとしよう。ここではそのことを「Cuillen」と呼ぶこととする。Cuillenディスカウントが受けられるのは、一度にタリスカー(訳注:ウィスキーの商品名)を5000ドル以上買った顧客だ。3000ドルづつ二回買い物をしても、それは無効。一度の買い物が5000ドルを超えなければならない。さて、ある顧客の去年一年間の買い物のうち、どの月がCuillenディスカウント適用月なのかを調べるとしよう。このときユーザーインターフェイスは考えないものとする。適用月が分かればそれで良しとする。
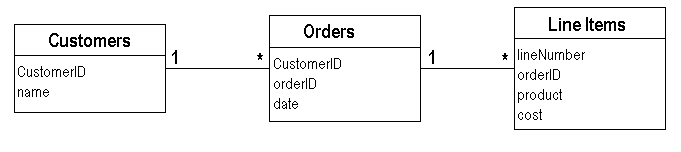
図1:例題用のデータベーススキーマ(UML記法)
いくつかやり方があるが、まずはよくある3つの解き方(transaction script, domain model, complex SQL)から始めよう。
今回、Rubyを使ってサンプルを作っている。いつもはJavaやC#(アプリケーション開発者が読めるC言語ベースのプログラミング言語)を使うのだが、まあいいややっちゃえーって思ってやってみた。Rubyを選んだのは実験でもある。私が Ruby が好きなのは、コンパクトながらも構造化されたコードが書けて、OO的なものを作るのが簡単だからだ。スクリプト言語はもうコレ。決まり。ここで使っているRubyのクイックガイドを作ったから、見ておくれ。
トランザクションスクリプト(Transaction Script)
トランザクションスクリプトとは、P of EAAの中で私が作ったパターン名である。リクエストによって処理を行う手続き型(a procedual style)のパターンのことだ。プロシージャは必要なデータをすべて読み込み、メモリ上でどの月が必要なのかを探し、それから処理を行うことになる。
def cuillen_months name
customerID = find_customerID_named(name)
result = []
find_orders(customerID).each do |row|
result << row['date'].month if cuillen?(row['orderID'])
end
return result.uniq
end
def cuillen? orderID
talisker_total = 0.dollars
find_line_items_for_orderID(orderID).each do |row|
talisker_total += row['cost'].dollars if 'Talisker' == row['product']
end
return (talisker_total > 5000.dollars)
end
この2つのメソッド(cuillen_months, cuillen?)は、ドメインロジックを含んでいる。メソッド内でデータベースにクエリを発行する ファインダーメソッド(find_XXX)が呼ばれている。
def find_customerID_named name
sql = 'SELECT * from customers where name = ?'
return $dbh.select_one(sql, name)['customerID']
end
def find_orders customerID
result = []
sql = 'SELECT * FROM orders WHERE customerID = ?'
$dbh.execute(sql, customerID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
def find_line_items_for_orderID orderID
result = []
sql = 'SELECT * FROM lineItems l WHERE orderID = ?'
$dbh.execute(sql, orderID) do |sth|
result = sth.collect{|row| row.dup}
end
return result
end
まあ、これは簡単に思いつくやり方だな。SQL は効果的に使われていないしな[これだとデータを取り出すのに複数回クエリを発行する必要がある(2 + N 回:Nは注文の回数)]。だが、今はあまり深く考えないこと。後から改良していくので。今はこのアプローチのエッセンスに注目すること。エッセンス:「扱うデータを一度に読み込み、ループでまわして、必要なものをセレクト」。
(ところで、上のドメインロジック。読みやすいけど、Rubyっぽくはない。できれば下のような、Rubyの強力なブロックとコレクションメソッドを使ったメソッドが望ましい。このコードを奇妙に思うひとも多いと思うが、Smalltalkerたちは喜んでくれると思う。)
def cuillen_months2 name
customerID = find_customerID_named(name)
qualifying_orders = find_orders(customerID).select {|row| cuillen?(row['orderID'])}
return (qualifying_orders.collect {|row| row['date'].month}).uniq
end
ドメインモデル(Domain Model)
さて次。古典的なオブジェクト指向ドメインモデルについて考えてみよう。ここでは、メモリ上にオブジェクトを作り、データベースのテーブル上にそれと同じ物を反映させる方法をとる(実際のシステムでは正確に一致することはないが)。ファインダーオブジェクト(finder object)がデータベースからオブジェクトを取り出し、一度メモリ上にオブジェクトを展開して、それからオブジェクト内でロジックを走らせている。
ファインダー(finder)から見ていこう。データベースにSQLをぶち込み、それからオブジェクトを作っている。
class CustomerMapper
def find name
result = nil
sql = 'SELECT * FROM customers WHERE name = ?'
return load($dbh.select_one(sql, name))
end
def load row
result = Customer.new(row['customerID'], row['NAME'])
result.orders = OrderMapper.new.find_for_customer result
return result
end
end
class OrderMapper
def find_for_customer aCustomer
result = []
sql = "SELECT * FROM orders WHERE customerID = ?"
$dbh.select_all(sql, aCustomer.db_id) {|row| result << load(row)}
load_line_items result
return result
end
def load row
result = Order.new(row['orderID'], row['date'])
return result
end
def load_line_items orders
#Cannot load with load(row) as connection gets busy
orders.each do
|anOrder| anOrder.line_items = LineItemMapper.new.find_for_order anOrder
end
end
end
class LineItemMapper
def find_for_order order
result = []
sql = "select * from lineItems where orderID = ?"
$dbh.select_all(sql, order.db_id) {|row| result << load(row)}
return result
end
def load row
return LineItem.new(row['lineNumber'], row['product'], row['cost'].to_i.dollars)
end
end
上記のloadメソッドは、以下のクラスをロードする。
class Customer...
attr_accessor :name, :db_id, :orders
def initialize db_id, name
@db_id, @name = db_id, name
end
class Order...
attr_accessor :date, :db_id, :line_items
def initialize (id, date)
@db_id, @date, @line_items = id, date, []
end
class LineItem...
attr_reader :line_number, :product, :cost
def initialize line_number, product, cost
@line_number, @product, @cost = line_number, product, cost
end
Cuillen月を決めるロジックは数メソッドで済む。
class Customer...
def cuillenMonths
result = []
orders.each do |o|
result << o.date.month if o.cuillen?
end
return result.uniq
end
class Order...
def cuillen?
discountableAmount = 0.dollars
line_items.each do |line|
discountableAmount += line.cost if 'Talisker' == line.product
end
return discountableAmount > 5000.dollars
end
これだとトランザクションスクリプトよりもコードは長くなる。だが、オブジェクトをロードするロジックと実際のドメインロジックとがちゃんと分割されている。ここがポイント。このドメインオブジェクト上であれば、どんな処理でも同じ読み込みロジックが使えるというわけ。つまり、小さなドメインロジックがもっとたくさんあっても、それぞれに読み込みロジックを実装する必要はなく、コードの長さがそこで相殺され、結果的に何ら問題にはならないわけだ。メタデータマッピングのような技術を使えば、ここのコストはさらに削減できる。
ただ、これでもまだSQLクエリが多いよなあ(2 + 注文の数 回)。
SQL内にロジック(Logic in SQL)
先ほどの2つは、データベースをストレージ同然に扱っている。やったことといえば、ごく簡単なフィルタリング機能を使って、テーブルからすべてのレコードを取り出しただけ。SQLはパワフルなクエリ言語なので、例で使ったものよりももっと凄いことが出来る。
では、SQLの機能を目一杯使ってみよう。
def discount_months customerID
sql = <<-END_SQL
SELECT DISTINCT MONTH(o.date) AS month
FROM lineItems l
INNER JOIN orders o ON l.orderID = o.orderID
INNER JOIN customers c ON o.customerID = c.customerID
WHERE (c.name = ?) AND (l.product = 'Talisker')
GROUP BY o.orderID, o.date, c.NAME
HAVING (SUM(l.cost) > 5000)
END_SQL
result = []
$dbh.select_all(sql, customerID) {|row| result << row['month']}
return result
end
これを「複雑なクエリ」と呼んだが、あくまでも先ほどの例で使った簡単な select と where だけのクエリと比べて複雑だ、という意味だ。SQLクエリはもっと複雑なことが出来る。ただ、アプリケーション開発者はこれくらい複雑なだけでも避けちゃうんだよね。
パフォーマンスを考慮する(Looking at Performance)
こういった問題を考える場合、みんなが最初に疑問に思うことは「パフォーマンス」についてだ。ただ個人的にはパフォーマンスは最初に考えることではないように思う。それよりも更新性に優れたコードを書くことに時間を費やすべきだ。それからプロファイラを使ってボトルネックを見つけ、その部分だけ処理の速い(だが少しだけ見にくい)コードと取り替えるといい。というのも、実際にパフォーマンスが求められる個所はシステムのほんのわずかな部分だからだ。それと、更新性に優れたコードであれば、パフォーマンスを改善するのは簡単だというのもある。
だがまあ、とりあえず、パフォーマンスのトレードオフについて考えることにしよう。私の小さなラップトップだと、複雑な SQL クエリは他の2つのアプローチよりも20倍も速かった。スッキリとした(でも時代遅れの)ラップトップからデータセンターのサーバにアクセスしたときのパフォーマンスなんかで結論を出すわけにはいかないが、複雑なクエリがこれほど速いとは思いもしなかった。
これは、メモリ上にロジックを置くアプローチ(in-memory approaches)の方に原因がある。これらは非効率な SQL クエリで書かれているのだ。説明の中でも言ったが、それぞれが別々にSQLクエリを発行し、顧客の注文を取得しているのだ(私のテストデータベースでは、顧客ひとりにつき1000件の注文がある)。
これをひとつのSQLクエリに書き換えることで、ここのロード時間を大幅に削減することが出来る。まずはトランザクションスクリプトから書き換えてみよう。
SQL = <<-END_SQL
SELECT * from orders o
INNER JOIN lineItems li ON li.orderID = o.orderID
INNER JOIN customers c ON c.customerID = o.customerID
WHERE c.name = ?
END_SQL
def cuillen_months customer_name
orders = {}
$dbh.select_all(SQL, customer_name) do |row|
process_row(row, orders)
end
result = []
orders.each_value do |o|
result << o.date.month if o.talisker_cost > 5000.dollars
end
return result.uniq
end
def process_row row, orders
orderID = row['orderID']
orders[orderID] = Order.new(row['date']) unless orders[orderID]
if 'Talisker' == row['product']
orders[orderID].talisker_cost += row['cost'].dollars
end
end
class Order
attr_accessor :date, :talisker_cost
def initialize date
@date, @talisker_cost = date, 0.dollars
end
end
これは大幅な変更である。だが、3倍のスピードになった。
ドメインモデルにも同じように変更を加えよう。ドメインモデルが複雑な構造であるメリットは分かっているはず。そう、ドメインオブジェクト内のビジネスロジックには一切手を触れず、読み込みメソッドを修正するだけでよいのだ。
class CustomerMapper
SQL = <<-END_SQL
SELECT c.customerID,
c.NAME as NAME,
o.orderID,
o.date as date,
li.lineNumber as lineNumber,
li.product as product,
li.cost as cost
FROM customers c
INNER JOIN orders o ON o.customerID = c.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE c.name = ?
END_SQL
def find name
result = nil
om = OrderMapper.new
lm = LineItemMapper.new
$dbh.execute (SQL, name) do |sth|
sth.each do |row|
result = load(row) if result == nil
unless result.order(row['orderID'])
result.add_order(om.load(row))
end
result.order(row['orderID']).add_line_item(lm.load(row))
end
end
return result
end
(すまん。ドメインオブジェクトを一切変更する必要ないと言ったが、あれはちょっと嘘。パフォーマンスを上げるためには顧客のデータ構造を array から hash に変える必要があったんだ。だが、何度も言うが、これは本当にオブジェクトの内部的な変更でしかない。ディスカウントの計算部分には何の影響も与えてはいない)
いくつかのポイントがある。まず最初。これは覚えておいて損はない。メモリ上のコードは、インテリジェントなクエリを使えばさらにスピードアップすることがある。それから次。データベースに何度も問い合わせていないか注意してみてみよう。読み込みを1回に出来ないか確認してみよう。ドメインモデルを使っているとき、これは見落としがちなことなんだ。クラスは1度しかアクセスしていないんじゃないかと勘違いしがちだからね(一度に一行ずつしか読み込まないひとを見たことがあるが、こんな頭おかしいやり方はレアケース)。
トランザクションスクリプトとドメインモデルとの一番大きな違いは、クエリ構造への影響である。トランザクションスクリプトの例では、まったく新しいスクリプトを作ったと言ってもよい。さらに言うと、似たようなデータを使っているドメインロジックスクリプトがたくさんあれば、それぞれを変更しなくてはならないことになる。一方、ドメインモデルを使うと、ドメインロジック部分はきれいに離されているため、何も変更せずに済む。ドメインロジックがたくさんあればあるほど、これは大きな違いになるだろう。これは、トランザクションスクリプトとドメインロジックのいずれかを選択する際の一般的なトレードオフである(ドメインモデルの場合、ドメインロジックがたくさんあればあるほど、ドメインロジックがデータベースにアクセスする部分の複雑なコード[いわば初期投資分だな]が回収できるってわけ)。
複数テーブルへのクエリでも、インメモリのアプローチは複雑なSQLよりも遅い(私が計測したときは6倍の時間がかかっていた)。これは理解できる。複雑なSQLは、レコードを選択し、データベース内でコストを合計し、ちょっとした値をクライアントに戻すだけでよいが、一方、インメモリアプローチでは、5000行を必死に集めて、それからクライアントに戻さなければならないからだ。
パフォーマンスが唯一の懸念事項ではない。だが、パフォーマンスを重視してしまうことが往々にしてある。ぜったい改良しなければならないボトルネックがあれば、他の要因はそりゃまあ二の次になるわな。結果として、ドメインモデルファンの多くは、最初からメモリ上でロジックを動かすようになる。で、ボトルネックが発生したときだけ、複雑なSQLクエリを使う、と。こうなる。
これも指摘しといたほうがいいかもしれない。この例から、データベースの強みが分かるのだ。多くのクエリは、ここでやったような強力な select や集約機能を使ってない。だから、こんなにパフォーマンスが変わることもない。あとひとつ。ユーザーが複数人いると、クエリの振る舞いが劇的に変わることがある。なので、実際のプロファイリングはちゃんと複数人の環境でやったほうがいい。単独のクエリでは発生しないような重たーいロックがかかったりするから。
更新性(Modifiability)
EAは寿命が長いので、これだけは覚えておいてもらいたい。「EAはこれからめちゃくちゃ変わる」。つまり、変更しやすいようシステムを設計しなくてはいかんわけだ。メモリ上にビジネスロジックを埋め込むのは、保守のためだと言っていい。
SQLはいろんなことが出来る。ただ、それには限度がある。ものすごくクレバーなコーディングを要求するものがあるのだ。たとえば、データセットのメジアンを一目見て分かるようアルゴリズムを組むとか。標準ではない拡張機能を使わざるを得ないものもある。ただそれだと、移植性は損なわれてしまう。
データベースにデータを格納する前に、ビジネスロジックを走らせたいことがよくある(特に情報が保留中の時など)。このとき、データベースにデータを入れてしまうと問題になることがある。一時的なデータ(pending session data)は本番用のデータ(fully accepted data)と別にしておきたいからだ。一時的なデータには、本番用データと同じ検証ルールを適用しないほうがよい。
分かりやすさ(Understandability)
SQLは特別な言語として見られがちだ。アプリケーション開発者はSQLを使わなくてもいいとまで言われている。データベースフレームワークを使えば、SQLを触らなくても済むとも言われている。私はこういった意見を聞くにつけ、ちょっとおかしいんじゃないかと思っている。ちょっとくらい複雑なSQLだったらぜんぜん平気だし、それで満足できているもの。だけど多くの開発者たちは、SQLはこれまでの言語に比べて扱いが難しいし、文法を理解できるのはSQLエキスパートだけだと思っているようだ。
いいテストがある。前述の3つのソリューションをみてみよう。そして、ドメインロジックを追うのが一番簡単なのはどれか、一番修正しやすいのはどれなのかを決めるのだ。私はドメインモデルバージョン(いくつかのメソッドだけのやつ)が一番コードを追いやすい(データベースアクセス部分が切り離されているからだ)。次はSQLバージョン(それからトランザクションスクリプト)。ただ、人によって好みはある。
もしチーム内にSQLに詳しいひとがいなかったら、ドメインロジックをSQLから切り離したほうがいい(と同時に、メンバにSQLのトレーニングをしたほうがいいだろう。せめて中位のレベルになるまでは)。このとき、チーム構成にも気を配ったほうがいい。人によってアーキテクチャが決定されることもあるからだ。
重複排除(Avoiding Duplication)
今まで出会ったものの中で、シンプルだが最もパワフルな設計原則。それは、「重複排除の原則」だ。これは『the Pragmatic Programmers(邦訳『達人プログラマー』)』の中で「DRY(Don’t Repeat Yourself)原則」として提唱されたものだ。
DRY原則をこのケースに適用して考えてみよう。このアプリケーションに別の仕様を加えことにする。「ある月の顧客の注文リストがある。注文には、注文ID、日付、合計金額、Cuillenに該当するかが表示されており、合計金額でソートされている」。
このクエリをドメインオブジェクトのアプローチを使って行おうとすれば、 注文クラスに合計金額を計算するメソッドを追加する必要がある。
class Order...
def total_cost
result = 0.dollars
line_items.each {|line| result += line.cost}
return result
end
適切な場所にメソッド置けば、注文リストを簡単に表示できる。
class Customer
def order_list month
result = ''
selected_orders = orders.select {|o| month == o.date.month}
selected_orders.sort! {|o1, o2| o2.total_cost <=> o1.total_cost}
selected_orders.each do |o|
result << sprintf("%10d %20s %10s %3s\n",
o.db_id, o.date, o.total_cost, o.discount?)
end
return result
end
同じことをSQL単体で行うとすれば、サブクエリ(a correlated sub-query)が必要となる。サブクエリ……怖いよね。
def order_list customerName, month
sql = <<-END_SQL
SELECT o.orderID, o.date, sum(li.cost) as totalCost,
CASE WHEN
(SELECT SUM(li.cost)
FROM lineitems li
WHERE li.product = 'Talisker'
AND o.orderID = li.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN lineItems li ON o.orderID = li.orderID
WHERE (c.name = ?)
AND (MONTH(o.date) = ?)
GROUP by o.orderID, o.date
ORDER BY totalCost desc
END_SQL
result = ""
$dbh.select_all(sql, customerName, month) do |row|
result << sprintf("%10d %20s %10s %3s\n",
row['orderID'],
row['date'],
row['totalCost'],
row['isCuillen'])
end
return result
end
人によってどっちが分かりやすいかは違うだろう。だが、ここで私が言いたいのは、重複についてである。今回のクエリは、単に月を返すだけの前回のクエリと重複している部分がある。ドメインオブジェクトのアプローチだと、この重複は起こらない。Cuillenの仕組みを変えたいと思っても、cuillen? メソッドを変更するだけで、すべてのユーザーがアップデートされる。
重複排除問題でSQLに触れないのはフェアではないだろう。リッチなSQLアプローチでも、重複問題を避けることは出来るのだ。データベース熱狂者は必死になってこう言うに違いない。ビューを使え、と。
ビューを定義しよう。下のクエリから Orders2 というビューを定義した。
SELECT TOP 100 PERCENT
o.orderID, c.name, c.customerID, o.date,
SUM(li.cost) AS totalCost,
CASE WHEN
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker'
AND o.orderID = li2.orderID) > 5000
THEN 'Y'
ELSE 'N'
END AS isCuillen
FROM dbo.orders o
INNER JOIN dbo.lineItems li ON o.orderID = li.orderID
INNER JOIN dbo.CUSTOMERS c ON o.customerID = c.customerID
GROUP BY o.orderID, c.name, c.customerID, o.date
ORDER BY totalCost DESC
これで、月を取得するのも、注文リストを作るのも、このビューから行うことが出来る。
def cuillen_months_view customerID
sql = "SELECT DISTINCT month(date) FROM orders2 WHERE name = ? AND isCuillen = 'Y'"
result = []
$dbh.select_all(sql, customerID) {|row| result << row[0]}
return result
end
def order_list_from_view customerName, month
result = ''
sql = "SELECT * FROM Orders2 WHERE name = ? AND month(date) = ?"
$dbh.select_all(SQL, customerName, month) do |row|
result << sprintf("%10d %10s %10s\n",
row['orderID'],
row['date'],
row['isCuillen'])
end
return result
end
このビューのおかげで、2つのクエリは簡単になり、キーとなるビジネスロジックもひとつの場所に置くことが出来た。
このようにビューを作って重複を回避することはあまり行われていないようだ。今までに読んだSQL本でもこういったことには触れていない。データベース開発者とアプリケーション開発者との間にギャップがあるために、こういったことを行うのも難しい場合がある。 アプリケーション開発者はビューを作らせてもらえず、データベース開発者はこういったビューを作らずにボトルネックを作り、アプリケーション開発者を困らせる。DBAは、ひとつのアプリケーションが必要だからといってビューを作るようなことはしない。SQLも、他のものと同じく、十分注意して設計する必要があると思うのだが。
カプセル化(Encapsulation)
カプセル化はよく知られたオブジェクト指向設計の原則だ。この原則はソフトウェア設計全般にも適用できるように思う。原則としてプログラムは、プロシージャコールインターフェイスの裏側にデータ構造を隠すモジュール群に分解されるべきだと言われる。これはシステムに大きな影響を与えずに基本データ構造を変更できるようにするためである。
すると、データベースはどうやってカプセル化すればよいだろう? うまい具合にカプセル化できると、アプリケーション全体を変更することなく、データベーススキーマを変更することが可能なはずだ。
企業アプリケーションをカプセル化する一般的なやり方は、レイヤ分けである。ドメインロジックをデータソースロジックから切り離すことが目的である。これで、ビジネスロジックを担当するコードがデータベース設計変更時に影響を与えられることはない。
ドメインモデルバージョンは上記のカプセル化の良い例である。ドメインロジックはメモリ上のオブジェクトでのみ動くようになっており、データを取得するところは完全に切り離されている。トランザクションスクリプトのアプローチだと result set が返ってくるのでデータベースの構造は分かってしまうが、 ファインダーメソッド(find_XXX)でデータベースはカプセル化されている。
アプリケーションの世界では、プロシージャやオブジェクトのAPI経由でカプセル化を行うことが出来る。SQLでそれに相当するものはビューである。もしテーブルを変更するとすれば、変更前の古いテーブルをサポートするビューを作ればよい。問題はアップデートだ。ビュー経由ではちゃんとアップデートが行われないことがある。多くのshopsがDML(Data Management Language)をストアドプロシージャでラップするのはこのためである。
カプセル化はビューの変更をサポートするだけじゃない。データへのアクセス部分とビジネスロジックの定義部分を分けるためにも役立つ。SQLを使ってしまうと、上記の2点ははっきりと分けることができない。だが、ある種のカプセル化を行うことは出来る。
たとえば、上でクエリ内の重複を避けるために作ったビューだが、 あのビューはデータソースビューとビジネスロジックビューに分けることが出来る。 データソースビューはこんな感じになる。
SELECT o.orderID, o.date, c.customerID, c.name,
SUM(li.cost) AS total_cost,
(SELECT SUM(li2.cost)
FROM lineitems li2
WHERE li2.product = 'Talisker' AND o.orderID =li2.orderID
) AS taliskerCost
FROM dbo.CUSTOMERS c
INNER JOIN dbo.orders o ON c.customerID = o.customerID
INNER JOIN dbo.lineItems li ON li.orderID = o.orderID
GROUP BY o.orderID, o.date, c.customerID, c.name
このビューは、よりドメインロジックにフォーカスした他のビュー内でも使うことができる。以下は、Cuillenに該当するかどうかを示すものだ。
SELECT orderID, date, customerID, name, total_cost,
CASE WHEN taliskerCost > 5000 THEN 'Y' ELSE 'N' END AS isCuillen
FROM dbo.OrdersTal
こういった考え方は、ドメインモデル内にデータを読み込む際にも使える。前もって、ドメインモデルのパフォーマンス問題にどう取り組めばよいか述べた。Cuillen月を取得する完全なクエリを使うか、それとも代わりにシングル SQL クエリを使うかという話だ。もうひとつの方法は、上記のデータソースビューを使う方法である。これを使えばドメインロジックをドメインモデルの中に入れたままハイパフォーマンスを維持できる。商品は必要なときに Lazy Loadで読み込まれる。それにあった要約情報は、ビュー経由で取得することができる。
ビューを使うと(もしくはストアドプロシージャを使うと)、ある程度カプセル化を行うことが出来る。多くのEAデータはいろいろな場所に存在している。様々なRDBだけでなく、レガシーシステムにも、他のアプリケーションにも、ファイルにもデータは含まれる。XMLが成長していけば、ネットワーク経由で平文のファイルを共有しあうこともあるだろう。この場合、アプリケーションコード内のレイヤでのみ完全なカプセル化を行うことが出来る。これは、ドメインロジックをメモリにおいたほうがいいということを示すことでもある。
データベース移植性(Database Portability)
開発者の多くが複雑なSQLを避けているのは、データベースの移植性に原因がある。標準SQLはどのデータベースでも使えたはずじゃなかったのか。だからデータベースの移植は簡単だったんじゃないのか。
実際は、そんなことはない。だいたい標準ではあるのだが、あちこちで躓くことになる。注意してSQLを作ればデータベースサーバを変更するのに手間がかからないこともない。ただそれだと、SQLの機能が大きく損なわれることになる(訳注:標準的なSQL機能しか互換性がない)。
データベースを移植するかどうかというのはプロジェクト次第だ。ただこれは、以前よりも問題にならなくなっている。データベース市場は拡大し、主要な3企業で占められており、企業はそのいずれかのデータベース会社と強力に結びついているからだ。データベースの変更要請がないのであれば、持っているデータベースの特別な機能を十分活用したほうが良い。
移植性が必要なひともまだいる。複数のデータベースと接続できる製品を提供しているひとたちだ。安全に使用できるのはどのSQLなのか注意しなくてはならないと言って、彼らはロジックをSQLに埋め込むことに強く反対している。
テストの容易性(Testability)
テストの容易性は設計の話題にあまりあがらない。テスト駆動型開発(TDD)の良さは、テストの容易性が設計に欠くことのできないものであることを再認識させてくれたところにある。
実務ではSQLのテストは行われていないように思う。重要なビューやストアドプロシージャが構成管理ツール上に置かれているのさえ見たことが無い。テストが容易なSQLを作ることは、確実に出来る。データベース環境でテストできるxunitツールがいくつかあったはずだ。テストができるようにテストデータベースを作るといったEvolutionary database(日本語訳:データベースの進化的設計)テクニックは、TDDプログラマが楽しんでやっていることに非常に近い。
違いがよく分かるのはパフォーマンスである。製品の中にSQLを組み込むよりも、直接 SQL を発行した方が速いわけだが、ビジネスロジックのテストであればメモリ上で行ったほうがより速い。実際のデータベースに接続する代わりに Service Stubを使えるようデータベースまわりがきちんと設計されていたら、という話ではあるが。
まとめ(Summing Up)
いろいろ語ってきたけど、そろそろ結論。私がここで語ってきたいろんなことについて、あなた方はしっかりと考えなきゃいけない。あなた自身のバイアスをかけて、良いのか悪いのか判断して欲しい。それから、あなたがどのやり方を採用すればよいのかを決めて欲しい。リッチなクエリにドメインロジックを入れるのが本当に良いのかどうか。
私が状況を考察するときに注意するのは、データが論理的にひとつのRDBに存在しているのか、それとも分散して存在して(SQLは使えないで)いるのかという点である。データが分散しているようであれば、データソース層をカプセル化して、ドメインロジックをメモリ上に置くようにすると良い。SQLが強力であっても、ここでは意味がない。SQLが使えないデータソースもあるからだ。
データのほとんどが論理的にひとつのデータベースに格納されている場合、けっこう面白いことになる。まず2つ考えることがある。ひとつはプログラム言語は何にするか(SQLかアプリケーション用の言語か)。もうひとつは、どこでコードを走らせるかである(SQLを使ってデータベース上で走らせるか、それともメモリ上か)。
SQLによって簡単になることもあるし、難しくなることもある。SQLが簡単だと思う人もいれば、何がなんだかよくわからないっていう人もいる。ここでは、その人が快適かどうかというのが大切だ。ロジックをSQLに入れるならば、移植性は諦めた方がいい(ベンダ依存の拡張機能を使って楽しんでいるだろうし)。移植性を確保しておきたいのなら、SQLにロジックを入れないこと。
これまで更新性について述べてきた。これはまず先に考えなければならないものだと思う。だが、致命的なパフォーマンス問題が発生したらそちらを優先すべきだろう。インメモリのアプローチをとっている時にボトルネックが発生したら、強力なSQLを使って解決したほうがよい。上でまとめたように、クエリをデータソースよりに近づけたらどれだけパフォーマンスが上がるのかをちゃんと見ておいたほうが良いと思う。そうすることで、SQL内のドメインロジックを最小限にとどめることができるはずだから。
改定履歴(Revision History)
このドキュメントをアップデートしたらここに記述しておく。
'’February 2003’’:
- 日本語訳:kdmsnr
-
この記事の存在を教えてくれた、[[かくたに http://www.kakutani.com/compass/]]さんにピース。 - 牛尾剛さんの日本語訳を参考にしました。ありがとうございます。
-
arton様の[[ご指摘 http://arton.no-ip.info/diary/20031216.html#p06]]。どうも! -
[[ファウラーが立てた(?)スレ http://www.artima.com/forums/flat.jsp?forum=32&thread=4304]] - 2003-12-16 (火) 20:22:21 ‘’[[つとむくん]]’’ : portability は移植性ではないでしょうか?
- 2003-12-16 (火) 23:45:20 ‘’[[kdmsnr]]’’ : アルクもそうみたいですね。修正します。
- 2003-12-18 (木) 19:21:18 ‘’[[kdmsnr]]’’ : はんばあぐさんの日記よりhttp://sgtpepper.net/hyspro/diary/20031218.html#p03
- 2003-12-22 (月) 15:44:47 ‘’[[kdmsnr]]’’ : http://www.ku3g.org/negi/diary/?20031221#200312212
- 2003-12-22 (月) 15:45:59 ‘’[[kdmsnr]]’’ : http://arton.no-ip.info/diary/20031217.html#p04
- 2004-01-02 (金) 19:37:56 ‘’[[kdmsnr]]’’ : http://www.commentout.com/people/takai/diary/index.cgi/view/books/0321127420.html
- 2005-05-07 (土) 22:55:36 ‘’[[名無しさん]]’’ : http://c2.com/cgi/wiki?DomainLogicAndSqlArticle
- 2005-07-10 (日) 12:34:57 名無しさん : 「早い」は「速い」の間違い?
- 2005-10-25 (火) 22:28:27 kdmsnr : http://d.hatena.ne.jp/yuuntim/20051025#p1