ソースコードブランチ管理のパターン
https://martinfowler.com/articles/branching-patterns.html
最新のソース管理システムには、ソースコードのブランチを簡単に作成できる強力なツールが用意されています。しかし、最終的にはこれらのブランチをマージしなければならず、多くのチームは混み合ったブランチに対処するのに膨大な時間を費やしています。複数の開発者の作業をインテグレーションし、本番リリースまでの道筋を整理することに集中して、チームが効果的にブランチを利用できるようにするためのパターンがいくつかあります。全体的なテーマとしては、ブランチを頻繁にインテグレーションし、最小限の労力で本番環境に展開できる健全なメインラインを作ることに注力すべきだということです。
ソースコードは、どのようなソフトウェア開発チームにとっても重要な資産であり、何十年にもわたってコードを良い状態に保つための一連のソースコード管理ツールが開発されてきました。これらのツールは変更を追跡できるので、ソフトウェアの以前のバージョンを再現し、時間の経過とともにどのように発展しているかを確認することができます。これらのツールは、共通のコードベースで作業しているプログラマーのチームの調整の場としても機能します。各開発者が行った変更を記録することで、これらのシステムは一度に多くの作業を追跡することができ、開発者がこれらの作業をどのようにマージするかを検討するのに役立ちます。
このように開発作業を分割したり、マージしたりすることは、ソフトウェア開発チームのワークフローの中心であり、このような活動のすべてを管理するために、いくつかのパターンが進化してきました。ほとんどのソフトウェアパターンと同様に、すべてのチームが従うべき規範となるものはほとんどありません。ソフトウェア開発のワークフローは、特にチームの社会構造やチームが採用しているプラクティスといったコンテキストに大きく依存しています。
この記事での私の仕事は、これらのパターンを議論することであり、1 つの記事の中でパターンを説明しながら、コンテキストとそれらの間の相互関係をよりよく説明するための物語による説明を散りばめています。それらを区別しやすくするために、パターンの節には「✣」文字を付けています。
ベースパターン
パターンを考える上で、私は 2 つの主要なカテゴリに分けることが有用であると考えています。1 つはインテグレーション、つまり複数の開発者がどのように自分たちの仕事を組み合わせて首尾一貫したものにしていくかということに注目しています。もう 1 つは、本番環境へのプロセスについてです。このカテゴリでは、インテグレーションされたコードベースから本番環境で動作する製品に至るまでのプロセスを管理するために、ブランチを使用します。これらの両方を支えるいくつかのパターンがありますが、ここではベースパターンとして取り上げます。これらのパターンの中には、基本的なパターンでもなければ、2 つの主要なグループに当てはまらないパターンもいくつかあります。
✣ ソースブランチング ✣
コピーを作成し、そのコピーへのすべての変更を記録
複数の人が同じコードベースで作業していると、すぐに同じファイルで作業することができなくなります。私がコンパイルを実行しようとしているときに、同僚が式を入力している所だったらコンパイルに失敗してしまいます。そうなると、「コンパイル中だから、何も変えないでくれ」と怒鳴り散らさなければなりません。チームの人数が 2 人であってもこの状態は難しいでしょうし、より大きなチームではなおさら難しくなります。
これに対する簡単な答えは、各開発者がコードベースのコピーを持つということです。これで各人が自分の機能開発に簡単に取り組むことができるようになりましたが、新たな問題が発生します:開発が終わったときに 2 つのコピーをどうやって 1 つにマージするのかという問題です。
ソースコード管理システムによってこのプロセスをはるかに簡単にすることができます。重要なのは、各ブランチに加えられたすべての変更をコミットとして記録することです。これにより、誰もが utils.java への小さな変更を忘れないようにするだけでなく、変更を記録することによってマージを簡単に実行できるようになります。これは特に複数の人が同じファイルを変更する場合に顕著です。
これは、この記事で使用するブランチの定義につながります。私は、ブランチをコードベースへの一連のコミットとして定義します。ブランチのヘッドまたはティップは、その中の最新のコミットです。

ここではブランチという名詞の定義をしましたが、「分岐する」という動詞もあります。これは新しいブランチを作成する事を意味しますが、元のブランチを 2 つに分割すると考えることもできます。ブランチのマージとは、あるブランチからのコミットを別のブランチに適用する事を意味します。
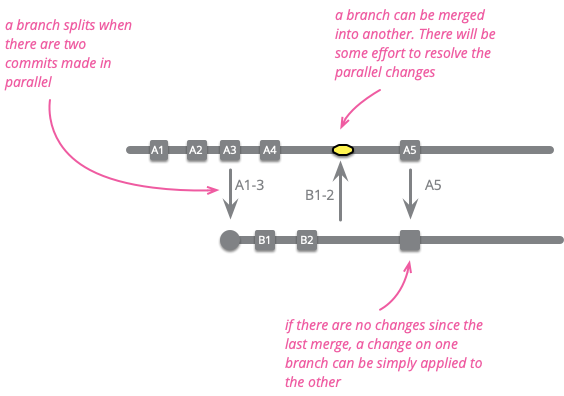
ここでの「ブランチ」の定義は、ほとんどの開発者が語るブランチに基づいています。しかし、ソースコード管理システムでは「ブランチ」という言葉をより特化した意味合いで使う傾向にあります。
最近の開発チームでは、ソースコードを共有の git リポジトリに保管していることがよくあります。ある開発者の一人(名前をスカーレットとしましょう)が少し変更を加えたいと思い、git リポジトリをクローンして master ブランチをチェックアウトしました。彼女はいくつかの変更を加えて master ブランチにコミットします。一方、もう一人の開発者 (名前をバイオレットとしましょう) は、リポジトリを自分のデスクトップにクローンして master ブランチをチェックアウトしました。スカーレットとバイオレット は同じブランチで作業しているのでしょうか、それとも別のブランチで作業しているのでしょうか?二人とも “master” で作業していますが、コミットはお互いに独立していて、変更を共有リポジトリにプッシュするときにマージする必要があります。スカーレットが自分が行った変更がよくわからなくなってきたので、一旦最後のコミットをタグ付けして master ブランチを origin/master (共有リポジトリからクローンした最後のコミット) にリセットした場合はどうなるでしょうか?
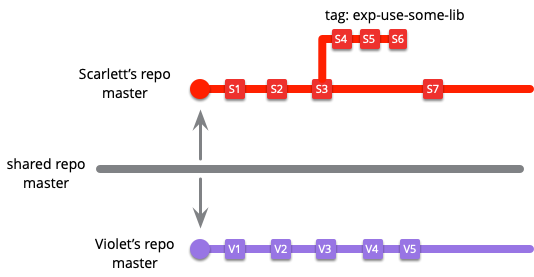
先ほどのブランチの定義によると、スカーレットとバイオレットは別々のブランチで作業をしています。またこのどちらのブランチも共有リポジトリの master ブランチとも異なります。スカーレットがタグ付けして作業を脇に置いたとしても、私の定義によればそれはブランチです (彼女もそれをブランチと考えているかもしれません)。しかし、git の用語ではこれはタグと呼びます。
git のような分散型のバージョン管理システムでは、リポジトリをクローンするたびにブランチが追加されることになります。スカーレットがローカルのリポジトリをラップトップにクローンして電車で帰宅すると、3 つ目の master ブランチができたことになります。同じ効果は GitHub でフォークした場合でも発生します - フォークされたリポジトリにはそれぞれのブランチを持ちます。
他のバージョン管理システムではブランチの定義が異なるため、この用語の混乱はさらに深刻になります。git のブランチと Mercurial のブランチはまったく異なり、Mercurial のブックマークに近いものです。Mercurial では名前のないヘッドを使ってブランチすることもできますし、Mercurial ユーザーはリポジトリをクローンしてブランチすることもよくあります。
このような用語の混乱のために、この用語を避ける人もいます。ここで役立つのが、より一般的な用語である「コードライン」です。私はコードラインをコードベースの特定のバージョンのシーケンスと定義しています。コードラインはタグで終わることもあればブランチであることもありますし、git の reflog で迷子になることもあります。私が定義したブランチとコードラインの間には強い類似性があることに気づくでしょう。コードラインのほうがいろいろな意味で便利な用語で、私も使っていますが、実際にはあまり広く使われていません。ですからこの記事では、git (あるいは他のツール) の用語の文脈でない限り、ブランチとコードラインを同じ意味で使います。
この定義の結果、どのようなバージョン管理システムを使っているにせよ、開発者はローカルで変更を加えるとすぐに自分のマシン上の作業コピーに少なくともひとつの個人的なコードラインを持っているということになります。プロジェクトの git リポジトリをクローンして master をチェックアウトし、いくつかのファイルを更新すると、コミットをしていなくてもそれは新しいコードラインとなります。同様に、suberversion リポジトリのトランクの作業コピーを自分で作った場合は、たとえ subversion ブランチがなくても、その作業コピーはそれ自身のコードラインとなります。
いつ使うべきか
古いジョークで、高いビルから落ちた場合、落ちるということだけでは怪我はしないが着地の際に怪我をする、というものがあります。ソースコードでは、ブランチを切ることは簡単ですが、マージするのは大変です。
コミット時にすべての変更を記録するソース管理システムは、マージのプロセスを容易にはしますが、依然として取るに足らないことではありません。スカーレットとバイオレットがともに変数名を変更する際、異なる名前に変更した場合、ソース管理システムはこの衝突を解決できないため人間による介入が必要となります。さらに厄介なことに、この種のテキストの衝突は、少なくともソースコード管理システムが発見して人間に注意を促すことができます。しかし、テキストが問題なくマージされていても、システムが動作しないような衝突が発生することがよくあります。スカーレットが関数の名前を変更し、バイオレットがその関数を古い名前で呼び出すコードを彼女のブランチに追加したとします。これを意味的衝突と呼んでいます。このような衝突が起こると、システムはビルドに失敗したり、ビルドしても実行時に失敗したりします。
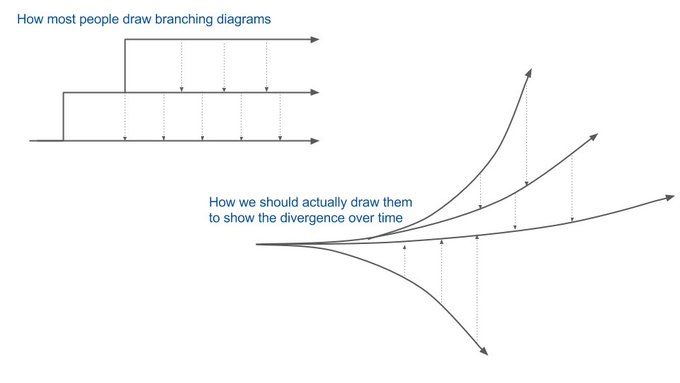
この問題は、並行コンピューティングや分散コンピューティングを扱ったことがある人ならよく知っていることです。開発者が、共有された状態(コードベース)に対して並列に更新を行っている状態です。これらの変更について合意形成して直列化することで、どうにかして結合する必要があります。システムが正しく実行されるようにするには、共有された状態の有効性について非常に複雑な基準を持つ必要がある事実によって、私たちの作業はさらに複雑になっています。合意を見つけるための決定論的アルゴリズムはありません。人間が合意を見つける必要があり、その合意には異なる更新を混ぜ合わせることが必要かもしれません。合意に至るために、元の更新を変更して衝突を解決するしかない場合も多いです。
まず「もしブランチがなかったら?」と考えてみましょう。誰もがコードを直接編集していて、中途半端な変更によってシステムに支障をきたし、互いに足を引っ張り合うでしょう。そこで私たちは、システムを変更しているのは自分たちだけで、その変更はシステムを危険にさらす前に、完全に出来上がるまで待つことができるよう、時間を止めることができるかのような錯覚を個人に与えています。しかし、これは幻想であり、最終的にはその代償を支払うことになります。誰が支払うのか?いつ?どれくらい?この費用を持つ代わりになるものがないか、それがこれらのパターンで議論していることです。 – ケント ベック
したがって、この記事の残りの部分では、私は快適に隔離された場を提供し、ビルから落ちるときのような風の勢いを感じることのできるような様々なパターンを提供します。これらのパターンによって、地面に激突するという不可避の衝撃を最小化することができます。
✣✣✣
✣ メインライン ✣
プロダクトの現在の状態を表す単一の共有ブランチ
メインラインは、チームのコードの現在の状態を表す特別なコードラインです。新しい作業を始めたいときはいつでも、メインラインから自分のローカルリポジトリにコードをプルして作業を開始します。自分の作業をチームの他のメンバーと共有したいときはいつでも、自分の変更内容でそのメインラインを更新します。その際、理想的には後述するメインラインインテグレーションを使います。
チームによってこの特別なブランチの名前を使い分けていますが、バージョン管理システムの慣習によって決まることが多いです。git ユーザーは “master” と呼びますし、subversion ユーザーは “trunk” と呼びます。
ここで強調しておきたいのは、メインラインは単一の共有コードラインであるということです。git で “master” と言うと、それはいくつかの異なる意味を持つことがあります。なぜなら、各リポジトリクローンは各自のローカル master を持つからです。通常、このようなチームはオリジンリポジトリを持ち、その master がメインラインとなります。ゼロから新しい仕事を始めるということは、そのオリジンリポジトリをクローンすることを意味します。すでにクローンを作成している場合は、master をプルしてメインラインの最新の状態にすることから始めます。
自分の機能に取り組んでいる間は、自分の個人的な開発ブランチを持っていて、それはローカルの master であったり、別のローカルブランチを作ったりします。私がしばらく作業している間は、メインラインの変更を定期的にプルし、それを私の個人開発ブランチにマージすることで、メインラインの最新の変更に追随することができます。
同様に、リリースに向けて新しいバージョンを作成したい場合は、現在のメインラインから始めることができます。リリースに向けて製品を十分に安定させるためにバグを修正する必要がある場合は、リリースブランチを使うことができます。
いつ使うべきか
2000 年代初頭にクライアントのビルドエンジニアに話を聞きに行ったことを覚えています。彼の仕事は、チームが取り組んでいる製品のビルドを組み立てることでした。彼はチームのすべてのメンバーにメールを送り、メンバーのコードベースでインテグレーションの準備ができているさまざまなファイルを送信してもらっていました。そして、それらのファイルをインテグレーションツリーにコピーし、コードベースのコンパイルを試みます。通常、コンパイルが通り何らかの形でのテストの準備ができたビルドになるまでに数週間かかりました。
対照的に、メインラインでは誰でもメインラインのティップのプロダクトの最新のビルドからすぐに始めることができます。さらに、メインラインはコードベースの状態を見やすくするだけではなく、これから紹介する他の多くのパターンの基礎にもなります。
メインラインの代替案の一つにリリーストレインがあります。
✣✣✣
✣ 健全なブランチ ✣
各コミットで自動チェック、通常はビルドとテストを実行し、ブランチに不具合がないことを確認する
メインラインはこのように共有され、承認されたステータスを持っているので、安定した状態を維持することが重要です。2000 年代初頭にも、各製品のビルドを毎日行うことで有名な別の組織のチームと話をしたことがあります。当時、これはかなり先進的なことと考えられていて、この組織はそれをやっていることで賞賛されていました。ただし、当時言及されていませんでしたが、このようなデイリービルドは常に成功していたわけではありませんでした。実際、デイリービルドで数ヶ月間コンパイルが失敗し続けているというチームも珍しくありませんでした。
これに対処するためには、ブランチを健全な状態に保つこと、つまりビルドが成功し、バグがあるにしてもほとんどない状態でソフトウェアが動くようにすることです。これを確実にするためには、自己テストコードを書くことが非常に重要であることがわかりました。この開発方法は、本番用のコードを書くときに、自動テストを包括的に書くことを意味しており、これらのテストに合格すれば、コードにバグが含まれていないことを確信できるようにします。このようにすれば、コミットするたびにビルドを実行することで、 ブランチを健全に保つことができます。このビルドにはこのテストスイートの実行も含まれています。システムのコンパイルに失敗したり、テストに失敗したりした場合は、そのブランチで他のことをする前にそれらを修正することが最優先です。多くの場合、これはブランチを「フリーズ」させることを意味します - ブランチを健全な状態に戻すための修正以外のコミットは許されません。
コードが健全であると十分自信を持つために必要なテストには対立する事項があります。より徹底したテストの多くは実行に多くの時間を必要とし、コミットが健全かどうかのフィードバックを遅らせることになります。チームは、デプロイメントパイプライン上でテストを複数のステージに分けることでこれに対処します。これらのテストの第一段階は、通常は 10 分以内という短時間で実行されるべきですが、それでもある程度包括的なものでなければなりません。私はこのようなテスト群をコミットスイートと呼んでいます (ただし、コミットテスト群は通常ほとんどがユニットテストであるため、「ユニットテスト」と呼ばれることが多いです)。
理想的には、すべてのテストがすべてのコミットで実行されるべきです。しかし、テストが遅い場合、例えばサーバを数時間専有する必要があるパフォーマンステストのようなものは現実的ではありません。最近では、チームは通常、すべてのコミットで実行できるコミットスイートを構築し、デプロイメントパイプラインの後の段階を可能な限り頻繁に実行することができます。
コードがバグなく動作しているだけでは、コードが優れているとは言えません。安定したペースでデリバリーを維持するためには、コードの内部品質を高く保つ必要があります。そのための一般的な方法としてレビュー済みコミットが挙げられますが、これから述べるようにその他の選択肢もあります。
いつ使うべきか
各チームは、開発ワークフローにおける各ブランチの健全性について明確な基準を持つべきです。メインラインを健全に保つことには計り知れない価値があります。メインラインが健全であれば、開発者は現在のメインラインをプルするだけで新しい作業を始めることができ、作業の邪魔になる不具合に巻き込まれることはありません。新しい作業を始める前に、プルしてきたコードのバグを修正したり、回避したりするために何日も費やしている人の話をよく耳にします。
健全なメインラインは、プロダクションへの道のりもスムーズにします。新しいプロダクション候補は、メインラインのヘッドからいつでも構築することができます。最良のチームではこのようなコードベースを安定させるための作業をほとんど必要とせず、多くの場合メインラインからプロダクションに直接リリースすることができます。
健全なメインラインを維持するために重要なのは、数分で実行できるコミットスイートを備えた自己テストコードです。これを実現するには大きな投資が必要になりますが、コミットが数分以内で何も壊れていないことを確認できるようになれば、開発プロセス全体が完全に変わります。変更をより迅速に行い、自信を持ってコードをリファクタリングして作業しやすくし、要望からそれを形にしてプロダクションでコードを実行するまでのサイクルタイムを大幅に短縮することができます。
個人的な開発ブランチについては、Diff デバッグが可能になるので、健全な状態を維持するのが賢明です。しかしこれは、作業状態を頻繁にチェックポイントするためにコミットを行うことと逆行します。別の実装を試す場合にはたとえコンパイルが失敗するとしても一旦チェックポイントを作るかもしれません。私がこの対立を解消する方法は、当面の作業が終わったら、不健全なコミットをスカッシュ(訳注 複数のコミットを一つにまとめること)することです。そうすることで、数時間後には健全なコミットだけが私のブランチに残るようになります。
私の個人ブランチを健全な状態にしておけば、メインラインへのコミットも楽になります。そうしておくことで、メインラインインテグレーションでエラーが発生した場合でも、私のコードベース内のエラーが原因ではなく、純粋にインテグレーションの問題によるものだとわかります。これにより、それらのエラーを見つけて修正するのがずっと早く簡単になります。
✣✣✣
インテグレーションパターン
ブランチとは、隔離とインテグレーションの相互作用を管理することです。全員が一つの共有コードベースで常に作業をしていると、変数名を入力している最中にプログラムをコンパイルできなくなるので、うまくいきません。だから少なくともある程度の間、自分が作業できるプライベートなワークスペースという概念が必要なのです。最近のソースコード管理ツールを使えば、簡単にブランチを切って、そのブランチへの変更を監視することができます。しかし、どこかの時点でインテグレーションする必要があります。ブランチ戦略を考えることは、いつどのようにインテグレーションするかを決めることです。
✣ メインラインインテグレーション ✣
開発者は、メインラインからプルしたり、マージしたり、メインラインにプッシュすることで、自分の作業をインテグレーションします。
メインラインは、チームのソフトウェアの現在の状態がどのようなものであるかを明確に定義します。メインラインを使う最大のメリットは、インテグレーションが簡単になることです。メインラインがなければ、上で説明したようにチーム内の全員と調整するという煩雑な作業が発生します。しかし、メインラインがあれば、各開発者は自分でインテグレーションすることができます。
これがどのように機能するのか、例を挙げて説明します。ある開発者 (ここではスカーレットと呼ぶことにします) は、メインラインを自分のリポジトリにクローンして作業を始めます。git では、この作業は clone (クローンがない場合) し、master ブランチに切り替えて master を自分のリポジトリにプルします。これで、ローカルでの作業、つまりローカルの master にコミットすることができるようになります。

彼女が仕事をしている間に、同僚のバイオレットがメインラインにいくつかの変更をプッシュします。スカーレットは自分のコードラインで仕事をしているので、自分の仕事をしている間バイオレットの変更に気を使う必要はありません。

ある時点で、彼女はインテグレーションしたいと思うポイントに到達します。この最初の作業は、メインラインの現在の状態を彼女のローカルの master ブランチにフェッチすることです。これによりバイオレットの変更がプルされます。彼女がローカル master で作業している間は、コミットは別のコードラインとして origin/master に現れます。
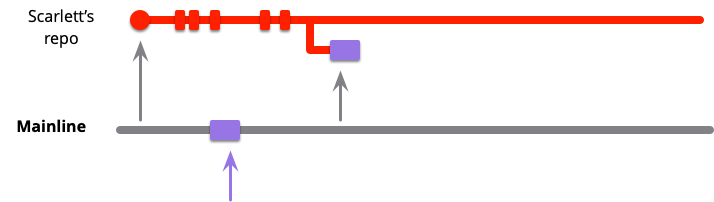
今、彼女は自分の変更とバイオレットの変更をインテグレーションする必要があります。これをマージで行うチームもあれば、リベースで行うチームもあります。一般的には、ブランチをまとめるという話をするときには、実際に行う操作が git のマージなのかリベースなのかに関わらず「マージ」という言葉を使います。ですから、実際にマージとリベースの違いについて議論しているのでなければ、「マージ」という言葉はマージとリベースのどちらでも実現できる論理的なタスクだと考えてください。
単純なマージを使う、ファストフォーワードマージを使う/使わない、リベースを使う/使わないは別の議論になります。それはこの記事の範囲外ですが、もし十分な数の Tripel Karmeliet (訳注 ベルギーのビール)が送られてきたら、その問題についての記事を書くかもしれません。結局のところ、見返りが必要です。
スカーレットが運が良ければ、バイオレットのコードをマージしても問題は起きませんが、そうでなければいくつかの衝突が発生します。これらはテキスト上の衝突かもしれません。これはほとんどの場合、ソース管理システムが自動的に対処します。しかし、意味的な衝突は対処するのがはるかに難しく、自己テストコードが非常に有効な領域です。(衝突はかなりの量の作業を発生させる可能性があり、常に多くの作業のリスクを伴うので、私はそれらに黄色の警告マークを付けます)。
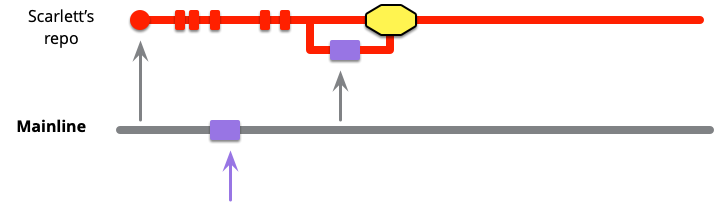
この時点で彼女は正常にメインラインを彼女のコードラインにプルしてきましたが、- これは重要かつ見落とされがちなことなのですが - 彼女はまだメインラインとのインテグレーションを完了していません。インテグレーションを完了するためには、彼女は自分の変更をメインラインにプッシュしなければなりません。彼女がこれを行わない限り、チームの他の全員は彼女の変更から隔離されてしまい、本質的にはインテグレーションされていません。インテグレーションにはプルとプッシュの両方があります - スカーレットがプッシュして初めて、彼女の作業がプロジェクトの残りの部分とインテグレーションされます。
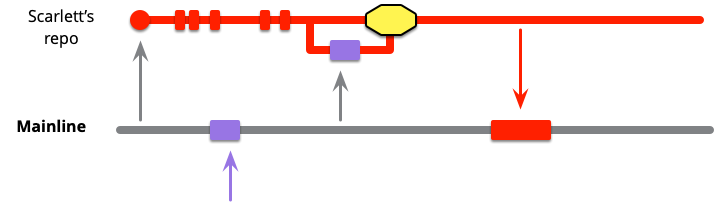
最近の多くのチームでは、コミットがメインラインに追加される前にコードレビューを必須としています - これは レビュー済みコミットと呼ばれるパターンで後ほど議論します。
スカーレットがプッシュする前に 他の誰かがメインラインにインテグレーションすることもあります。その場合、彼女は再びプルしてマージしなければなりません。通常、これはたまにしか起こらない問題で、これ以上の調整をしなくても解決できます。ビルド時間の長いチームでは、インテグレーションバトンと彼らが呼ぶバトンを持っている開発者だけがインテグレーションできるようにしているのを見たことがあります。しかし、ビルド時間が改善されるにつれ、最近ではそのような話はあまり聞かなくなりました。
いつ使うべきか
その名の通り、メインラインが存在している場合にのみ、メインラインインテグレーションを使うことができます。
メインラインインテグレーションの代替案の一つは、メインラインからプルしてその変更を単に個人開発ブランチにマージすることです。これは便利です。プルすることで、少なくとも他の人がインテグレーションした変更をスカーレットに知らせたり、自分の仕事とメインラインの間の衝突を検出したりすることができます。しかし、スカーレットがプッシュするまで、バイオレットは自分の作業とスカーレットの変更との間の衝突を検出することができません。
人が「インテグレーション」という言葉を使うとき、この重要なポイントを見落としていることが多いです。単にメインラインをプルしているだけなのに、メインラインを自分のブランチにインテグレーションしていると言うのはよく聞く話です。私はそのことに注意して、単にプルしているだけなのか、それとも適切なメインラインのインテグレーションを意味しているのかを確認するために、さらに質問するようになりました。この二つの結果は大きく異なるので、用語を混同しないようにすることが重要です。
もう一つの代替案は、スカーレットがチームとの完全なインテグレーションの準備ができていない状態、バイオレットの作業と衝突しているがそれでも彼女とコードを共有したいと思っている場合、に使われます。この場合、コラボレーションブランチを開くことができます。
✣✣✣
✣ フィーチャーブランチ ✣
ある機能のためのすべての作業を専用のブランチに置き、機能が完成したらメインラインにインテグレーションする。
フィーチャーブランチでは、開発者はある機能の作業を始めるときにブランチを開き、その作業が終わるまでその機能の作業をそのブランチ上で続け、メインラインとのインテグレーションを行います。
例えば、スカーレットを見てみましょう。彼女は、地方消費税の徴収をウェブサイトに追加するための機能に取り組むとします。彼女はプロダクトの現在の安定版から始め、メインラインを自分のローカルリポジトリにプルしてきて、現在のメインラインのヘッドから新しいブランチを作成します。彼女は、そのローカルブランチへの一連のコミットを行いながら、必要なだけこの機能に取り組んでいます。
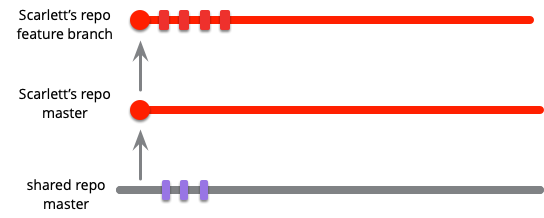
彼女はそのブランチをプロジェクトのリポジトリにプッシュして、他の人が彼女の変更を見られるようにするかもしれません。
彼女が作業をしている間、他のコミットもメインラインにやってきます。そのため、彼女は時々メインラインからプルしてくるでしょう。
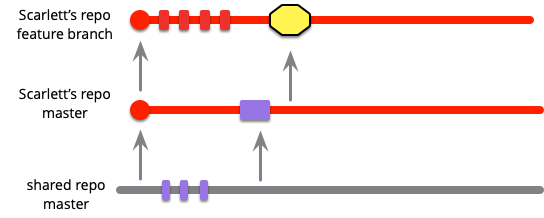
彼女はメインラインにプッシュしていないので、これは上述したようなインテグレーションにはあてはまらないことに注意してください。この時点では、彼女だけが自分の作業を見ていて、他の人は見ていません。
チームによっては、インテグレーションされているかどうかに関わらず、すべてのコードが共有リポジトリに保存されているようにしたい場合があります。この場合、スカーレットは自分のフィーチャーブランチを共有リポジトリにプッシュします。これにより、他の人の作業とまだインテグレーションされていなくても、他のチームメンバーが彼女の作業を見ることができるようになります。
彼女がその機能の作業を終えたら、メインラインインテグレーションを実行して、その機能を製品に組み込むのです。
スカーレットが同時に複数の機能に取り組んでいる場合、彼女はそれぞれ別のブランチを開きます。
いつ使うべきか
フィーチャーブランチは、今日の業界でよく使われているパターンです。いつ使うべきかを語るために、その主要な代替案である継続的インテグレーションを紹介する必要があります。しかし、その前に、インテグレーションの頻度について説明する必要があります。
✣✣✣
インテグレーションの頻度
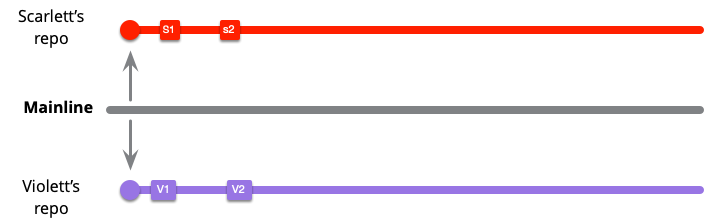
インテグレーションをどのくらいの頻度で行うかは、チームの運営方法に非常に強力な影響を与えます。State Of DevOps Reportの調査によると、業績の高い開発チームは業績の低い開発チームよりもインテグレーションの頻度が高いことが示されています。この結果は私や多くの私の同業者の経験と一致します。スカーレットとバイオレットを主人公にした 2 つのインテグレーション頻度の例を考えて、このことがどのように表れているかを説明します。
低頻度のインテグレーション
まず低頻度のケースから始めましょう。ここでは二人の登場人物がメインラインをローカルにクローンして仕事を始める所からスタートします。そしてまだプッシュしないローカルコミットをいくつかします。
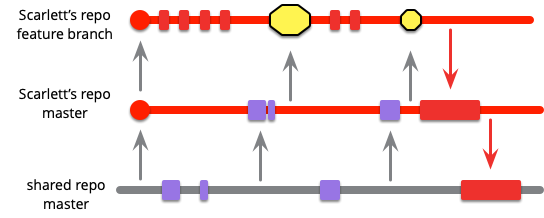
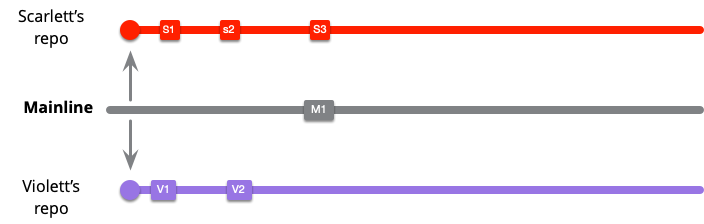
彼らが作業している間に、誰かがメインラインにコミットします。(他の色が入った人名が思いつかない - グレイハムかな?)
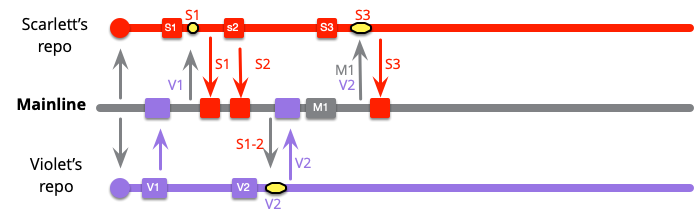
このチームは、健全なブランチを維持し各コミット後にメインラインからプルすることで作業を進めます。スカーレットは最初の 2 回のコミットではメインラインが変更されていなかったので何もプルするものがありませんでしたが、今は M1 をプルする必要があります。
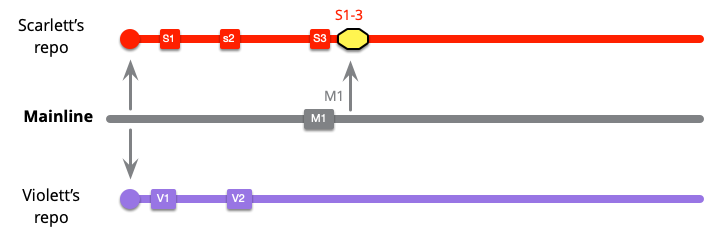
黄色のボックスでマージを表しています。これはコミット S1 から S3 に M1 にマージしたものです。すぐにバイオレットも同じことをする必要があります。
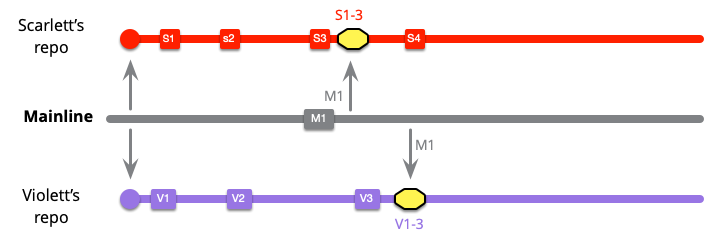
現時点では、どちらの開発者もメインラインに対して最新の状態ですが、お互いに孤立しているのでインテグレーションはしていません。スカーレットはバイオレットが V1 から V3 で行った変更に気付いていません。
スカーレットは更にいくつかのローカルコミットを行い、メインラインとのインテグレーションを行う準備ができました。スカーレットは先に M1 をプルしていたので、これは簡単なプッシュです。
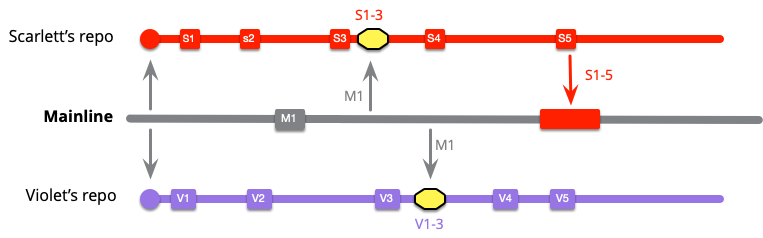
しかし、バイオレットにはもっと複雑な問題があります。彼女がメインラインのインテグレーションをするとき、S1 から S5 と V1 から V6 をインテグレーションしなければなりません。
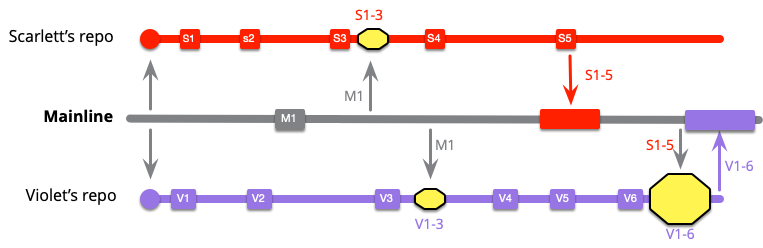
ここで私は、コミット数の多さからマージの大きさを割り出しました。この冗談を差し引いても、バイオレットのマージが一番難しい可能性が高いことがわかると思います。
高頻度のインテグレーション
先ほどの例では、2 人の開発者が幾つものローカルコミットの後にインテグレーションしました。彼らがローカルコミットのたびにメインラインインテグレーションを行うとどうなるか見てみましょう。
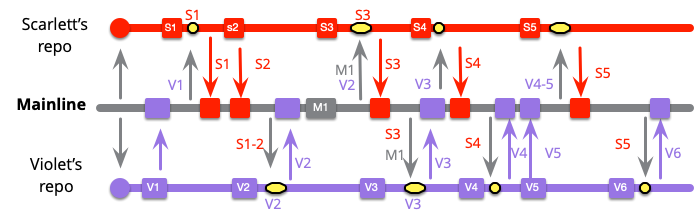
最初の変化は、バイオレットの最初のコミットで明らかです。メインラインは変更されていないので、これは単純なプッシュです。

スカーレットの最初のコミットにもメインラインのインテグレーションがありますが、バイオレットが先にインテグレーションしたので、マージが必要です。しかし、V1 と S1 をマージするだけなので、マージ量は少ないです。

スカーレットの次のインテグレーションは単純なプッシュです。つまり、バイオレットの次のコミットはスカーレットの最新の 2 つのコミットとのマージが必要になります。とはいえ、バイオレットのコミットとスカーレットの 2 つのコミットをマージするという、かなり小さなマージです。
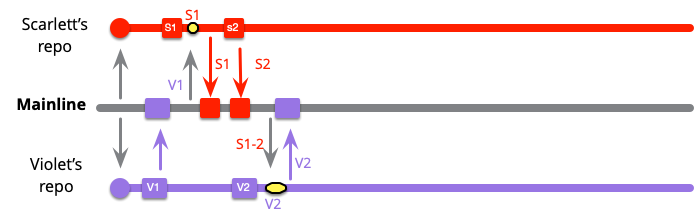
メインラインにその他のプッシュが行われた場合も、スカーレットとバイオレットの通常のインテグレーションでプルされます。
以前と似ているとはいえ、インテグレーションの規模は小さくなっています。スカーレットは今回、S1 と S2 がすでにメインラインにあったため、S3 と M1 をインテグレーションするだけで済みます。つまり、グラハムは M1 をプッシュする前に、すでにメインラインにあったもの(S1…2、V1…2)をインテグレーションしなければならなかったということになります。
開発者たちは残りの作業を続け、コミットごとにインテグレーションしていきます。
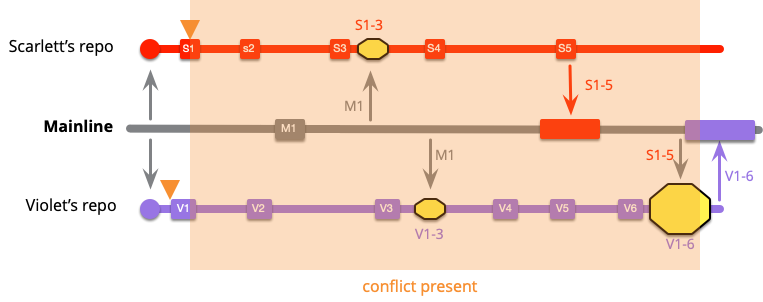
インテグレーションの頻度の比較
2 つの全体図を再度見てみましょう。
低頻度
高頻度
ここでは 2 つの明らかな違いがあります。第一に、高頻度のインテグレーションは、その名の通り、より多くのインテグレーションを行っています - 今回のおもちゃのようなの例だけで 2 倍です。しかし、より重要なことは、これらのインテグレーションは低頻度の場合よりもはるかに小さいということです。インテグレーションが小さいということは、衝突が発生する可能性のあるコード変更が少ないため、作業が少なくて済むということです。しかし、作業が少ないということよりも重要なのは、リスクが少ないということです。大規模なマージの問題は、それに伴う作業ではなく、その作業の不確実性にあります。大抵の場合、大規模なインテグレーションもスムーズに進みますが、時に非常に非常に悪い結果になることもあります。この時々降りかかる痛みというのは、通常の痛みよりもたちの悪いものです。常に 1 回のインテグレーションに 10 分余分に時間をかけるのと、50 分の 1 の確率で 6 時間かけてインテグレーションを修正する必要がでるのとでは、どちらがいいでしょうか?トータルの労力だけを見れば、8 時間 20 分ではなく 6 時間なので、50 分の 1 の方が良いでしょう。しかし、不確実性があるからこそ、50 分の 1 のケースはよりたちが悪く感じられ、不確実性がインテグレーションの恐怖につながるのです。
インテグレーションの恐怖
何度か悪いマージの経験をすると、チームはインテグレーションに慎重になる傾向があります。これは正のフィードバックループになりやすく、多くの正のフィードバックループと同様に、非常にネガティブな結果をもたらします。 最も明白な結果は、チームがインテグレーションを行う頻度が減ることで、より厄介なマージインシデントが発生し、これによって更にインテグレーションの頻度が減るというループになるということです。 さらに微妙な問題は、チームがインテグレーションが難しくなるだろうと考えている作業をやめてしまうことです。特に、これはリファクタリングに抵抗感を抱かせてしまいます。しかし、リファクタリングを減らすと、コードベースがますます不健全になり、理解や修正が難しくなり、チームの機能提供が遅くなります。機能を完成させるのに時間がかかるので、インテグレーションの頻度がさらに減少し、衰弱する正のフィードバックループを助長します。 直感的ではないですが、このような状況に対する答えは、 「痛みがあることはもっとやれ」 というスローガンに集約されています。
この頻度の違いを別の視点から見てみましょう。スカーレットとバイオレットの最初のコミットで衝突が発生した場合はどうなるのでしょうか?彼らはいつ衝突が発生したことに気づくのでしょうか?低頻度の場合、バイオレットの最後のマージまで気づくことができません。しかし、高頻度の場合は、スカーレットの最初のマージで気づくことができます。
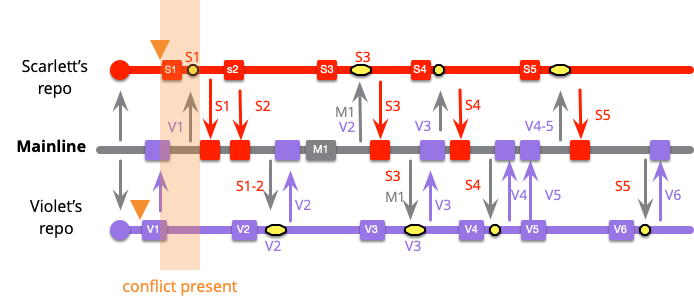
頻繁にインテグレーションを行うことで、マージの頻度は高まりますが、その複雑さとリスクは軽減されます。また、頻繁にインテグレーションを行うことで、チームの衝突にいち早く気づくことができます。もちろん、この 2 つのことには関連性があります。厄介なマージは通常、チームの作業の中に潜んでいた衝突の結果であり、インテグレーションが行われて初めて表面化します。
例えばバイオレットが請求書の計算の作業をしていて、税金の評価の処理の箇所で既存のコードの作者が特定の課税メカニズムを想定していたとしましょう。彼女の機能では異なる税金の処理が必要なので、直接のルートは、請求計算から税金を取り出して、後で別の関数に切り出すという方法です。課金計算は数箇所からしか呼び出されていなかったので、Move Statements to Callersを使うのは簡単で、結果的にプログラムの今後の進化のためにはより意味のあるものになりました。しかし、スカーレットはバイオレットがこのようなことをしていることを知らず、請求機能が税金の処理をしていると仮定して彼女の機能を書きました。
ここで、自己テストコードは私たちの救世主となります。強力なテストスイートがあれば、それを健全なブランチの一部として使用することで、衝突を発見することができるので、本番環境にバグが発生する可能性ははるかに低くなります。しかし、強力なテストスイートがメインラインのゲートキーパーとして機能していても、大規模なインテグレーションはものごとを困難にします。インテグレーションしなければならないコードが多ければ多いほど、バグを見つけるのが難しくなります。また、複数の干渉バグが発生する可能性も高くなり、理解するのが非常に困難になります。自己テストコードによって目を通すべきコミット数が少なくて済むだけでなく、Diff デバッグを使用することで、どの変更が問題を引き起こしたのかを絞り込むことができます。
多くの人が気づいていないのは、ソース管理システムはコミュニケーションツールであるということです。これにより、スカーレットはチームの他の人が何をしているかを見ることができます。頻繁にインテグレーションを行うことで、衝突が発生したときにすぐに警告が出るだけでなく、みんなが何をしているのか、コードベースがどのように進化しているのかをより意識するようになります。私たちは、個人が独立してハッキングしているようなものではなく、チームで協力して作業しているのです。
インテグレーションの頻度を高めることは、機能のサイズを小さくする重要な理由ですが、それ以外にもメリットがあります。機能が小さければ小さいほど、構築するのが早くなり、プロダクションに乗るのも早く、その価値を提供し始めるのも早くなります。さらに、機能を小さくすることでフィードバックの時間が短縮されるため、チームは顧客のことをもっと知りながら、より良い機能の決定を下すことができるようになります。
✣ 継続的インテグレーション ✣
開発者は、共有可能で健全なコミット、大抵は一日の作業より小さい単位で、すぐにメインラインにインテグレーションする。
チームが高頻度でのインテグレーションがより効率的でストレスが少ないことを経験したら、「どのくらいの頻度でインテグレーションできるのか」という疑問が自然と湧いてきます。フィーチャーブランチによって、チェンジセットの最小のサイズが決まります。つまり、まとまりのある機能より小さくはできないということです。
継続的インテグレーションを効果的に行う方法の詳細については、私の詳細な記事を参照してください。さらに詳しい情報は、Paul Duvall、Steve Matyas、Andrew Glover の著書を参照してください。Paul Hammant は、trunkbaseddevelopment.com で継続的インテグレーションのテクニックを満載したウェブサイトを管理しています。
継続的インテグレーションでは、インテグレーションのトリガーが異なります。つまり、機能開発にある程度の進捗があり、ブランチが健全であるときにはいつでもインテグレーションするのです。機能が完全であることを期待するのではなく、コードベースに価値のある変更があった場合にインテグレーションします。経験則としては、「誰もが毎日メインラインにコミットする」、正確には「1 日以上の作業がインテグレーションされていない状態でローカルリポジトリにあってはいけない」ということです。実際には、継続的インテグレーションの実践者のほとんどは、1 日に何度もインテグレーションを行い、1 時間分の作業かそれ以下の作業を喜んでインテグレーションしています。
継続的インテグレーションを使用する開発者は、部分的に構築された機能を頻繁にインテグレーションするという考え方に慣れる必要があります。また、稼働中のシステムで部分的に構築された機能を公開することなく、これを行うにはどうすればよいかを考える必要があります。たいてい、これは簡単です。クーポンコードに基づいた割引アルゴリズムを実装しているとすると、そのクーポンコードがまだ有効なリストにない場合、本番環境であっても私のコードは呼び出されません。同様に、保険金請求者に喫煙者かどうかを尋ねる機能を追加している場合、機能をビルドしてコードの背後にあるロジックをテストし、その質問をする UI を機能を最終的に構築するタイミングまで残しておくことで、本番では使用されないことを確認することができます。Keystone Interface を最後に結合することで、部分的にビルドされた機能を隠すことは、しばしば効果的なテクニックです。
✣✣✣
フィーチャーブランチと継続的インテグレーションの比較
現在、業界で最も一般的なブランチ戦略はフィーチャーブランチであるように思われますが、継続的インテグレーションの方が大抵は優れたアプローチであると主張する実践者のグループが存在します。継続的インテグレーションが提供する主な利点は、より高い、多くの場合ははるかに高いインテグレーション頻度をサポートしていることです。
インテグレーション頻度の違いは、チームの機能をどれだけ小さくできるかに依存します。チームの機能をすべて 1 日以内に完成させることができれば、フィーチャーブランチと継続的インテグレーションの両方を実行できます。しかし、ほとんどのチームはこれよりも長い期間のフィーチャーを持っており、フィーチャーの期間が長くなればなるほど、2 つのパターンの差は大きくなります。
すでに指摘したように、インテグレーションの頻度が高いほど、インテグレーションへの関与が少なくなり、インテグレーションへの恐怖心が薄れます。これは、伝わりにくいことが多いです。数週間や数ヶ月ごとにインテグレーションする世界で生きてきた人は、インテグレーションは非常に困難に満ちた活動になる可能性が高いです。一日に何度もインテグレーションができるということはとても信じてもらえないでしょう。しかし、インテグレーションは「頻度は難易度を下げる」という類のもののひとつです。「辛いことはより頻繁にやれ」というのは直観的ではない考え方です。しかし、インテグレーションが小さければ小さいほど、悲惨で絶望だらけの壮大なインテグレーションになる可能性は低くなります。フィーチャーブランチではより小さな機能、つまり数週間ではなく数日で終わるべきと主張しています(数ヶ月もかかるのは論外です)。
継続的インテグレーションでは、機能の長さとインテグレーションの頻度を切り離して、高頻度のインテグレーションのメリットを享受することができます。チームが 1 ~ 2 週間で開発できるサイズの機能を開発する場合、継続的インテグレーションでは、最高のインテグレーション頻度のメリットをすべて享受しながら、そのような規模の機能を実現することができます。また、マージのサイズも小さくなるため、作業量も少なくて済みます。さらに重要なことは、上で説明したように、マージを頻繁に行うことで、厄介なマージのリスクを減らすことができ、それによってもたらされる悪い意味の驚きを排除し、マージに対する全体的な恐怖心を減らすことができます。コード内で衝突が発生した場合でも、高頻度でインテグレーションを行うことで、厄介なインテグレーション問題が発生する前に素早く発見することができます。これらの利点は非常に強力なので、完成まで数日しかかからない機能を開発する際にも継続的インテグレーションを行っているチームがあるほどです。
継続的インテグレーションの明らかな欠点は、メインラインへのインテグレーションが閉じていないという点です。これは好ましくないだけでなく、チームが健全なブランチを維持することが得意でない場合にはリスクとなります。ある機能のすべてのコミットをまとめておくと、その機能を次のリリースに含めるかどうかの判断を遅らせる事が可能となります。機能フラグを使ってユーザーの視点で機能のオン/オフを切り替えることができますが、機能のコードはプロダクトに含まれます。結局コードがプロダクトに含まれても目に見えるものではないのでこういった懸念は大げさなものではありますが、継続的インテグレーションを行うチームは、1 日に何度もインテグレーションが行われていてもメインラインが健全であることを確信できるように、強力なテスト体制を構築しなければなりません。このスキルを想像するのが難しいと感じるチームもあれば、可能だし解放感があると感じるチームもあります。この前提条件が意味する所は、健全なブランチを実現しておらず、リリース前にコードを安定させるためにリリースブランチを必要とするチームにとってはフィーチャブランチの方が良いということです。
マージの大きさや不確実性はフィーチャブランチの最も明白な問題ですが、最大の問題はリファクタリングを妨げるという点かもしれません。リファクタリングは、定期的に行われ、摩擦が少ないときに最も効果的になります。リファクタリングによって衝突を発生させるかもしれませんが、衝突を迅速に発見して解決しなければ、マージは困難になります。したがって、リファクタリングは高頻度のインテグレーションと合わせて行われる時が最も効果的です。そのため、継続的インテグレーションをプラクティスの一つとして考えているエクストリームプログラミングの一部としてリファクタリングが人気を博したのは当然のことです。フィーチャーブランチはまた、開発中の機能とは関係のない変更を行うことを防ぐため、徐々にコードベースを改善するリファクタリングの妨げとなります。
私たちは、trunk にマージされるまでのライフサイクルが非常に短い(1 日未満)ブランチやフォークを持ち、アクティブなブランチは合計で 3 つ以下であることが、継続的なデリバリの重要な側面であり、すべてがより高いパフォーマンスに貢献していることを発見しました。また、コードを毎日 trunk や master にマージすることも同様です。
– State of DevOps Report 2016
私はソフトウェア開発の実践に関する科学的な研究について、大抵はその方法論に重大な問題があり納得できません。一つの例外は、State Of Dev Ops Reportです。このレポートでは、ソフトウェアデリバリパフォーマンスの指標を開発していますが、この指標は、より広い組織のパフォーマンスの指標と相関しており、投資対効果や収益性などのビジネス指標と相関しています。2016 年にそのレポートで初めて継続的インテグレーションを評価したところ、ソフトウェア開発パフォーマンスの向上に貢献していることがわかり、その後の調査でも繰り返し同じ結果となっています。
継続的インテグレーションを使用することで、機能を小さく保つことの他の利点がなくなるわけではありません。小規模な機能を頻繁にリリースすることで、迅速なフィードバックサイクルが生まれ、プロダクトの改善に大きく貢献します。継続的インテグレーションを使用する多くのチームは、プロダクトに少しずつ機能を追加し、新機能を可能な限り頻繁にリリースするように努めています。
フィーチャーブランチ
✔ フィーチャー内のすべてのコードは、一つの単位として品質を評価することができる
✔ 機能コードは、機能が完了した場合にのみプロダクトに追加される
☓ マージの頻度が低い
継続的インテグレーション
✔ 機能の開発期間よりも高い頻度でインテグレーションすることができる
✔ 衝突を見つける時間を短縮
✔ より小さなマージ
✔ リファクタリングを奨励
☓ ブランチを健全に保つことが必要(したがって、自己テストコードも必要)。
✔ ソフトウェア・デリバリー・パフォーマンスの向上に寄与するという科学的根拠
フィーチャーブランチとオープンソース
多くの人がフィーチャーブランチの人気は GitHub とオープンソース開発で生まれたプルリクエストモデルに依ると考えています。そのことを考えると、オープンソースの仕事と商用ソフトウェア開発の多くの間に存在する全く異なる文脈を理解することは価値があります。オープンソースプロジェクトは様々な方法で構造化されていますが、一般的な構造は、一人の人間、または小さなグループがメンテナとしてプログラミングの大部分を行うというものです。メンテナは、貢献者であるプログラマの大規模なグループと協力して作業します。メンテナは通常、貢献者のことを知らないので、貢献者が貢献したコードの品質を知ることができません。また、メンテナは、貢献者が実際にどれだけの時間を作業に費やしているのか、また、貢献者がどれだけ効果的に物事を成し遂げることができるのかについても、ほとんど確信が持てません。
この文脈では、フィーチャーブランチは非常に理にかなっています。誰かが大なり小なり機能を追加しようとしていて、それがいつ完成するか(もしくは完成するかどうかすら)わからない場合、それが完成するまで待ってからインテグレーションするのが理にかなっています。また、コードをレビューして、コードベースの品質基準をクリアしているかどうかを確認することも重要です。
しかし、多くの商用ソフトウェアチームでは、作業環境が非常に異なっています。フルタイムのスタッフで構成されたチームがあり、その全員が、通常はフルタイムで、そのソフトウェアにかなりの時間を割いています。プロジェクトのリーダーはこれらの人たちのことをよく知っていて(彼らが始めたばかりの時以外は)、コードの品質とデリバリの能力について確たる期待を持つことができます。彼らは給与を得ているので、リーダーはプロジェクトに費やす時間やコーディング標準やグループの習慣などについて、より大きなコントロールを持つこともできます。
このような全く異なる文脈を考えると、このような商用チームのブランチ戦略は、オープンソースの世界で展開されているものと同じである必要はないことは明らかです。継続的インテグレーションは、オープンソースにたまに貢献する人にとっては不可能に近いが、商業的な業務には現実的な代替手段です。チームは、オープンソース環境で機能していることが、自分たちの異なる文脈で自動的に正しいと思い込んではいけません。
✣ レビュー済みコミット ✣
メインラインへのすべてのコミットは受け入れる前にレビューを行う。
コードレビューは、コードの品質を向上させ、モジュール性や可読性を向上させ、欠陥を取り除くための方法として、長い間奨励されてきました。にもかかわらず、企業組織では、ソフトウェア開発のワークフローに組み込むのが難しいことがよくありました。しかし、オープンソースの世界では、プロジェクトへの貢献は、プロジェクトのメインラインに受け入れる前にレビューされるべきだという考え方が広く採用され、このアプローチは、近年特にシリコンバレーを中心とした開発組織に広く浸透しています。このようなワークフローは、GitHub のプルリクエストの仕組みに特によくマッチします。
このようなワークフローは、スカーレットがインテグレーションしたい作業の塊を完成させるところから始まります。彼女はビルドが成功したらメインラインインテグレーションを行うように(チームがそれを実践していると仮定して)、メインラインにプッシュする前にコミットをレビューしてもらいます。チームの他のメンバー (例えばバイオレット) がそのコミットのコードレビューを行います。彼女がそのコミットに問題を見つけた場合コメントをし、スカーレットとバイオレットの両方が満足するまでやりとりをします。両者の作業が完了して初めて、そのコミットはメインラインにインテグレーションされます。
レビュー済みコミットはオープンソースで広まっていますが、それはプロジェクトにコミットしているメンテナと時々コントリビュートする人がいるという組織モデルに非常によく合っているためです。メンテナはどのような貢献にも目を光らせることができます。また、フィーチャーブランチと組み合わせると、フィーチャーブランチ上で機能が完成したタイミングでコードレビューを行うことができるので相性は抜群です。コントリビュータが機能を完成させるかどうかわからない場合、なぜそのコントリビュータの部分的な作業をレビューする必要があるのでしょうか?機能が完成するまで待つ方が良いでしょう。Google と Facebook は、この作業をスムーズに行うための特別なツールを構築しています。
タイムリーにコミットをレビューするための規律を作り上げることも重要です。もし開発者がある仕事を終えて、レビューコメントを待つ間数日間別の仕事をしていた場合、レビューコメントが戻ってきた頃にはその仕事のことはもう頭の中にはありません。これは完成した機能の場合でもイライラしますが、部分的に完成した機能の場合には、レビューが確認されるまでそれ以上の作業を進めることが困難になる可能性があるためより悪い事態になることがあります。原則として、レビュー済みコミットで継続的インテグレーションを行うことは可能であり、実際に Google はこのアプローチを採用しています。しかし、これは可能ではあるが、困難であり、比較的まれです。レビュー済みコミットとフィーチャーブランチの組み合わせのほうが一般的です。
いつ使うべきか
レビュー済みコミットは過去 10 年間で一般的になってきましたが、欠点や代替案もあります。うまくいったとしても、レビュー済みコミットは常にインテグレーションプロセスに追加の時間を必要とし、インテグレーションの頻度を下げることになります。ペアプログラミングは継続的なコードレビュープロセスを提供し、コードレビューを待つよりも速いフィードバックサイクルを提供します。(継続的インテグレーションやリファクタリングと同様に、ペアプログラミングも元々はエクストリームプログラミングのプラクティスの一つです)。
レビュー済みコミットを使用しているチームの多くは、レビューを十分に迅速に行っていません。その結果、レビューによる貴重なフィードバックが、有益なものになるには遅すぎるということが起きるのです。その時点で、多くの手直しをするか、うまくいくかもしれないがコードベースの品質を損なうものを受け入れるか、という厄介な選択を迫られることになります。
コードレビューは、コードがメインラインにインテグレーションされる前に限定されるものではありません。多くの技術リーダーはコミット後にコードをレビューし、開発者が懸念を感じたときに追いつくことが有用であると考えています。リファクタリングの文化がここでは役に立ちます。うまくいけば、チームの全員が定期的にコードベースをレビューし、目についた問題を修正するコミュニティを構築することができます。
レビュー済みコミットのトレードオフは、主にチームの社会構造にかかっています。すでに述べたように、オープンソースプロジェクトでは、一般的に信頼できるメンテナが数人、信頼できないコントリビュータが多数いる構造になっています。商用ソフトウェアを開発するチームはフルタイムであることが多いですが、似たような構造になっていることもあるかもしれません。プロジェクトリーダー (メンテナのようなもの) は、少数の (おそらく単数の) メンテナを信頼しており、チームの他のメンバーからのコードを警戒しています。チームのメンバーは一度に複数のプロジェクトに割り当てられることもあり、そういうケースではオープンソースのコントリビューターのようなものです。もしそのような社会構造が存在するならば、レビュー済みコミットやフィーチャーブランチは非常に意味のあるものです。しかし、より高い信頼度を持つチームは、インテグレーションプロセスに摩擦を加えることなくコードの品質を高く保つための他のメカニズムを発見することがよくあります。
つまり、レビュー済みコミットは貴重なプラクティスになるかもしれませんが、健全なコードベースを維持するためには決して必要な手段ではありません。特にリーダーに過度に依存しないバランスの良いチームを育てたいと考えているのであればなおさらです。
✣✣✣
インテグレーションへの摩擦
レビュー済みコミットの問題点の 1 つは、インテグレーションに手間がかかることが多いということです。これはインテグレーションへの摩擦の例であり、インテグレーションに時間がかかったり、インテグレーションに手間がかかったりする活動のことです。インテグレーションへの摩擦が多ければ多いほど、開発者はインテグレーションの頻度を下げようとする傾向があります。メインラインへのコミットには、記入するのに 30 分もかかるようなフォームが必要だと主張する(機能不全の)組織を想像してみてください。このような体制では、人々は頻繁にインテグレーションする気が失せてしまいます。フィーチャーブランチや継続的インテグレーションに対する姿勢がどうであれ、このような摩擦をもたらすものについてはよく検討することが重要です。それが明らかに価値を付加するものでない限り、そのような摩擦はすべて取り除くべきです。
マニュアルプロセスはよくある摩擦の原因となります。特に別の組織との調整を伴う場合は顕著です。この種の摩擦は、自動化されたプロセスを使用したり、開発者の教育を改善したり(必要性を排除するために)、マニュアルプロセスをデプロイメントパイプラインや本番環境での QA の後のステップに移動することで、多くの場合減らすことができます。この種の摩擦をなくすためのアイデアは、継続的インテグレーションと継続的デリバリの資料で見つけることができます。この種の摩擦は、本番までの道のりでも同じような困難さを生み出し、同じような対処法で対処可能です。
継続的インテグレーションを検討することに消極的になってしまうのは、インテグレーションの摩擦が激しい環境でしか仕事をしたことがない場合です。インテグレーションに 1 時間かかるのであれば、1 日に何回もインテグレーションを行うのは明らかに不合理です。誰もが数分でインテグレーションを済ますことができるような、インテグレーションするのが当たり前のチームに参加すると、別の世界のように感じます。フィーチャーブランチと継続的インテグレーションのメリットについての議論の多くは、これらの世界の両方を経験したことがないために、両方の視点を十分に理解できないために混乱しているのではないかと思います。
文化的要因もインテグレーションの摩擦に影響を与えます。特にチームメンバー間の信頼関係が及ぼす影響は顕著です。私がチームリーダーで、同僚はまともな仕事ができないと信頼していないとしたら、コードベースにダメージを与えるコミットを防ぎたいと思うでしょう。当然、これはレビュー済みコミットを推進する要因のひとつです。しかし、私が同僚の判断を信頼しているチームにいる場合、コミット後のレビューの方が適当であると考えたり、レビューを完全にカットして問題があれば共同でリファクタリングにあたるほうが良いと考えるでしょう。このような環境で私が得られるものは、コミット前のレビューがもたらす摩擦を取り除くことで、より高い頻度でのインテグレーションを促すことです。フィーチャーブランチと継続的インテグレーションの議論では、チームの信頼が最も重要な要素となることがよくあります。
モジュール性の重要さ
ソフトウェアアーキテクチャに関心を持つほとんどの人は、よく動作するシステムにおけるモジュール性の重要性を強調します。モジュール性の悪いシステムに小さな変更を加えなければならない場合、私はシステムのほとんどすべてを理解しなければなりません。なぜならたとえ小さな変更であっても、その影響がコードベース全体に広がるからです。しかし、優れたモジュール性を持つシステムでは、私が理解する必要があるのは、1 つか 2 つのモジュールのコードと、いくつかのモジュールへのインターフェースだけで、残りの部分は無視することができます。このように、理解するのに必要な労力を減らすことができるからこそ、システムの成長に合わせてモジュール化に力を入れる価値があるのです。
モジュール性はインテグレーションにも影響します。システムが良くモジュール分けされていれば、ほとんどの場合スカーレットとバイオレットはコードベースの中でうまく分離された部分で作業しているでしょうし、彼女らの変更が衝突を引き起こすことはありません。優れたモジュール性は、Keystone Interface や 抽象化によるブランチ のような技術を強化し、ブランチが提供する分離の必要性を減らします。しばしばチームは、モジュール性の欠如により他の選択肢がなくなるため、ソースブランチの使用を余儀なくされることがあります。
フィーチャーブランチは貧者のためのモジュラーアーキテクチャーです。つまり、ランタイムやデプロイ時に機能をかんたんに入れ替えることができるシステムを構築する代わりに、手動でマージすることによってソース管理ツールが提供してくれるフィーチャーブランチを使って結合させているのです。 – Dan Bodart
この話の結論はどちらの方向にも行きます。多くの試みにもかかわらず、プログラミングを始める前に良いモジュラーアーキテクチャを構築することは非常に困難です。モジュラー性を実現するためには、システムが成長していく様子を常に観察し、よりモジュラーな方向に向かうようにする必要があります。これを達成するためにはリファクタリングが鍵となり、リファクタリングには高頻度のインテグレーションが必要です。モジュール性と迅速なインテグレーションは、健全なコードベースの中で互いに支え合っています。
つまり、モジュール性を実現するのは難しいが、努力する価値はあるということです。その努力には、良い開発手法、デザインパターンについての学習、コードベースの経験からの学習が含まれます。乱雑なマージが発生した場合、蓋をしてしまいたい気持ちから閉じてしまうのではなく、なぜマージが乱雑なのかを考えてみてください。これを考えることはモジュール性をどのように改善し、コードベースの健全性を向上させ、チームの生産性を向上させるかについての重要な手がかりとなることが多いでしょう。
インテグレーションパターンについての個人的見解
著者としての私の目的は、特定の方向に従うようにあなたを説得するのではなく、あなたがどの方向に従うかを決定する際にあなたが考慮すべき要因について情報を伝えることです。それにもかかわらず、私が先に示したパターンの中でどちらが好きかについて、ここに私の意見を述べます。
全体的に、私は継続的インテグレーションを実践するチームで仕事をする方がずっと好きです。コンテキストが重要であり、継続的インテグレーションが最良の選択肢ではない状況はたくさんあると認識していますが、私はそのコンテキストを変えるための作業をしたいと考えています。私は、誰もが簡単にコードベースのリファクタリングやモジュール性の改善、コードベースを健全に保つことなど、変化するビジネスニーズに迅速に対応できるような環境に身を置いて欲しいと考えているからです。
最近では、私は開発者というよりもライターになっていますが、この働き方を好む人が多いThoughtWorksで働いています。これは、エクストリームプログラミングのスタイルは、ソフトウェア開発の最も効果的な方法の一つであり、職業上の能力を高めるために、このアプローチをさらに発展させていくチームを観察したいと思っているからなのです。
メインラインから本番リリースへの道のり
メインラインはアクティブなブランチで、新しいコードや修正されたコードが定期的に入ります。これを健全に保つことは、人々が新しい仕事を始めるときに安定した基盤から始めるために重要です。十分健全であれば、メインラインから直接本番環境にコードをリリースすることもできます。

メインラインを常にリリース可能な状態に保つというこの哲学は、継続的デリバリーの中心的な考え方です。そのためには、メインラインを健全なブランチとして維持するために、通常は集中的なテストをサポートするためのデプロイメントパイプラインを使用する決意とスキルが必要です。
この方法で作業しているチームは、通常リリースされたバージョンごとにタグを使用してリリースを追跡することができます。しかし、継続的なデリバリーを使用していないチームには、別のアプローチが必要です。
✣ リリースブランチ ✣
リリース準備の整ったバージョンを安定させるためのコミットのみを受け入れるブランチ
典型的なリリースブランチは、現在のメインラインからコピーしますが、新しい機能を追加することはできません。メインの開発チームは新しい機能をメインラインに追加し続け、これらは将来のリリースで取り上げられます。このリリースに取り組んでいる開発者たちは、リリースを本番環境にデプロイ可能な状態にすることを妨げるような不具合を取り除くことにのみ焦点を当てています。これらの不具合に対する修正はすべてリリースブランチで作成され、メインラインにマージされます。修正すべき不具合がこれ以上ない状態になったら、ブランチは本番リリースの準備ができているということです。
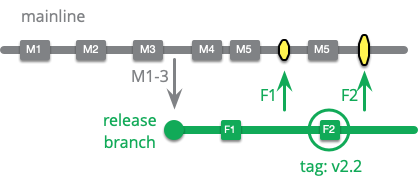
リリースブランチでの修正の作業範囲は (うまくいけば) 新しい機能コードよりも小さくなりますが、時間が経つにつれてそれらをメインラインにマージするのはどんどん難しくなります。ブランチは必然的に分岐するので、より多くのコミットがメインラインを修正することでリリースブランチをメインラインにマージするのが難しくなります。
この方法でリリースブランチにコミットする場合の問題点は、コミットをメインラインにコピーすることを怠ってしまうことです。コードベースの分岐によってこれは特に大きな問題となります。その結果導かれる結論は様々な問題を引き起こします。その結果、メインラインでコミットを作成し、それをリリースブランチにチェリーピックすることを好む人もいます。
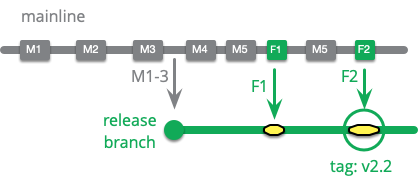
チェリーピックとは、ブランチがマージされていない状態で、あるブランチから別のブランチにコミットをコピーすることです。つまり、一つのコミットだけがコピーされ、そのブランチポイント以前のコミットはコピーされません。この例では、F1 をリリースブランチにマージすると、M4 と M5 がマージされます。しかし、チェリーピックでは F1 のみが対象となります。チェリーピックでは、F1 が M4 と M5 での変更に依存している可能性があるため、リリースブランチにきれいに適用されないこともありえます。
メインラインでリリース用の修正を書くことの欠点は、多くのチームではそれを行うのが難しく、メインラインで修正してもリリース前にリリースブランチで作業をし直さなければならないことにイライラするという点です。これは、リリースを出さなければならないというスケジュール上のプレッシャーがある場合に特に当てはまります。
一度に 1 つのバージョンしか運用していないチームには 1 つのリリースブランチしか必要ありませんが、製品によっては多くのリリースが運用されているものもあります。顧客のキット上で動作するソフトウェアは、顧客が希望する場合にのみアップグレードされます。多くの顧客はアップグレードに失敗して燃え尽きた経験があるため、魅力のある新機能がない限りアップグレードには消極的です。しかし、そのような顧客は、バグ修正、特にセキュリティ上の問題の修正は望んでいます。このような状況では、開発チームはまだ使われているリリースごとにリリースブランチをオープンにしておき、必要に応じて修正を適用します。
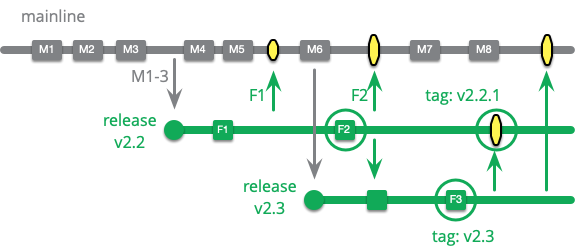
開発が進むにつれ、古いリリースに修正を適用することはますます難しくなりますが、それはしばしばビジネスを行うためのコストです。これは、顧客に頻繁に最新バージョンにアップグレードするよう奨励することによってのみ軽減することができます。これを奨励するには製品の安定性を維持することは不可欠です。一度アップグレードに問題があると、顧客は再び不必要なアップグレードを行うことに消極的になります。
(リリースブランチを表現する以下のような他の呼び名も聞いたことがあります。「リリース準備ブランチ」、「安定化ブランチ」、「候補ブランチ」、「ハードニングブランチ」などです。しかし、「リリースブランチ」が一番多いようです)
いつ使うべきか
リリースブランチは、チームがメインラインを健全な状態に保つことができない場合に貴重なツールです。これにより、チームの一部は本番環境にデプロイ可能になるよう必要なバグ修正に集中することができます。テスターは、このブランチのヘッドから最も安定した最近の候補をプルすることができます。誰もが製品を安定させるために何が行われたかを見ることができます。
こういったリリースブランチの価値にもかかわらず、ほとんどの優秀なチームは一つのバージョンのみを運用している製品にはこのパターンを使用しません。その必要がないからです。メインラインが十分に健全に保たれていれば、メインラインへのコミットはすべて直接リリースすることができます。その場合、リリースには公開されているバージョンとビルド番号をタグ付けする必要があります。
私が前の段落に「一つのバージョンのみを運用している」という枕詞を使っていることに気づいたかもしれません。これは、チームが本番環境で複数のバージョンを運用する必要があるときに、リリースブランチパターンは必要不可欠になるからです。
リリースブランチは、リリースプロセスに大きな摩擦があるときにも便利です。例えば、すべてのプロダクションリリースはリリース委員会によって承認されなければならないケースなどです。Chris Oldwood 氏が言う ように、「このような場合、リリースブランチは企業の歯車がゆっくりと回転する間の隔離ゾーンのような役割を果たします」。一般的に、このような摩擦は、インテグレーションへの摩擦を取り除く必要があるのと同じように、リリースプロセスから可能な限り取り除くべきです。しかし、モバイルアプリストアのように、それができない状況もあります。ほとんどの場合はタグで十分であり、ブランチはソースに必要な本質的な変更がある場合にのみ作成します。
リリースブランチは、そのパターンを使用する際の懸念事項を考慮して、環境ブランチにすることもできます。長く続くリリースブランチのバリエーションもありますが、これについては近日中に説明する予定です。
✣✣✣
✣ 成熟度ブランチ ✣
ヘッドがコードベースの成熟度が異なるそれぞれの最新バージョンを指すブランチ
チームはソースの最新バージョンがどれかを知りたいケースがよくありますが、コードベースの成熟度が異なると複雑になることがあります。QA エンジニアは製品の最新のステージングバージョンを見たいかもしれませんし、本番障害をデバッグしている人は最新の本番バージョンを見たいかもしれません。
成熟度ブランチは、これをトラッキングする方法を提供します。コードベースのバージョンがあるレベルに達すると、特定のブランチにコピーされます。
運用用の成熟度ブランチを考えてみましょう。本番リリースの準備ができたら、製品を安定させるためにリリースブランチを作ります。準備ができたら、生存期間の長い本番用のブランチにコピーします。私はこれをマージというよりはコピーと考えています。というのも、本番用のブランチを上流のブランチでテストされたものと全く同じコードにしているためです。
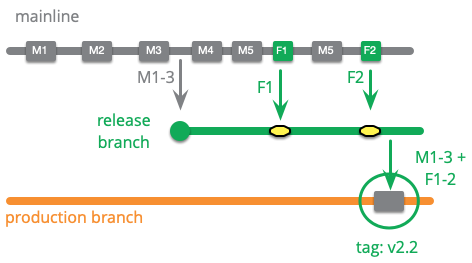
成熟度ブランチの魅力の一つは、リリースワークフローの各段階に到達したコードの各バージョンを明確にできるという点です。上の例では、M1 - 3 と F1 - 2 のコミットを組み合わせた単一のコミットを本番ブランチに行いたいだけです。SCM のちょっとしたテクニックがありますが、いずれにしても、メインラインの細かいコミットへのリンクが失われてしまいます。これらのコミットの情報もあとから追うことができるようにコミットメッセージに記録しておくべきです。
成熟度ブランチは通常、開発フローの適切なステージにちなんで命名されます。そのため、「本番ブランチ」、「ステージングブランチ」、「QA ブランチ」 などと呼ばれます。時折、本番ブランチを「リリースブランチ」と呼ぶケースもあります。
いつ使うべきか
ソース管理システムは、共同作業をサポートし、コードベースの履歴を追跡します。成熟度ブランチを使用することで、リリースワークフローの特定の段階のバージョン履歴を表示して重要な情報のいくつかを得ることができます。
現在運用中の本番コードなどについて、関連するブランチの先頭を見れば最新のバージョンを見つけることができます。以前はなかったと思われるバグが発生した場合は、そのブランチの以前のバージョンを見て、本番でのコードベースの変更点を確認することができます。
自動化は、特定のブランチの変更に結びつけることができます。例えば、本番用ブランチにコミットが行われるたびに、自動化されたプロセスでバージョンを本番用にデプロイすることができます。
成熟度ブランチを使用する代わりに、タグの命名規則を使うこともできます。あるバージョンが QA の準備ができたら、そのようにタグ付けします。典型的なタグ名ではビルド番号を含めます。つまり、ビルド番号 762 が QA の準備ができたら、”qa-762 “とタグ付けし、プロダクションの準備ができたら、”prod-762 “となります。そして、命名規則に一致するタグをコードリポジトリで検索することで、履歴を取得することができます。自動化も同様にタグの割り当てに基づいて行うことができます。
成熟度ブランチは、このようにワークフローに利便性を加えることができますが、多くの組織ではタグ付けで十分であることがわかっています。ですから、私はこれを、強いメリットもコストもないパターンの 1 つとして見ています。しかし、このようなトラッキングのためにソースコード管理システムを使用する必要があることは、チームのデプロイメントパイプラインが不十分であるという兆候であることがよくあります。
派生: 生存期間の長いリリースブランチ
これは、リリース候補のための成熟度ブランチとリリースブランチのパターンを組み合わせた派生形と考えることができます。リリースを行いたいときは、メインラインをこのリリースブランチにコピーします。リリースごとのブランチと同様に、リリースブランチへのコミットは安定性を向上させるためだけに行われます。これらの修正もメインラインにマージされます。リリースが発生したときにはタグを付け、別のリリースをしたいときにはメインラインをコピーして再度リリースを行います。
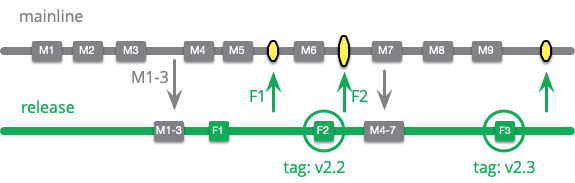
コミットは、成熟度ブランチでよく見られるようにコピーされたり、マージされたりします。マージする場合は、リリースブランチの先頭がメインラインの先頭と正確に一致しているか注意しなければなりません。これを行う一つの方法は、マージする前にメインラインに適用されていたすべての修正をリバートすることです。また、マージ後にスカッシュコミットを行い、それぞれのコミットが完全なリリース候補であることを確認するチームもあります(これが厄介だと感じる人は、リリースごとに新しいブランチを切った方が良いでしょう)。
この方法は、本番環境では単一のバージョンのみを運用している製品にのみ適しています。
チームがこのアプローチを好む理由のひとつは、最新のリリースブランチの先頭を探す必要はなく、リリースブランチの先頭が常に次のリリース候補を指していることを保証してくれるからです。しかし、少なくとも git では、チームが新しいリリースブランチを切るときにハードリセットして “release” ブランチの指し先を変更し、古いリリースブランチにタグを残しておくことで同じ効果を得ることができます。
✣✣✣
✣ 環境ブランチ ✣
ソフトウェアは通常、開発者のワークステーション、本番サーバー、そしておそらく様々なテスト環境やステージング環境など、異なる環境で実行する必要があります。通常、これらの異なる環境で実行するには、データベースへのアクセスに使用する URL、メッセージングシステムの場所、主要なリソースの URL などの設定を変更する必要があります。
環境ブランチとは、異なる環境で動作するように製品を再構成するためにソースコードに適用されるコミットを含むブランチのことです。バージョン 2.4 をメインラインで実行していて、それをステージングサーバーで実行したいとします。これを行うには、バージョン 2.4 から始まる新しいブランチを作成し、適切な環境変更を適用し、製品を再構築し、ステージング環境にデプロイします。
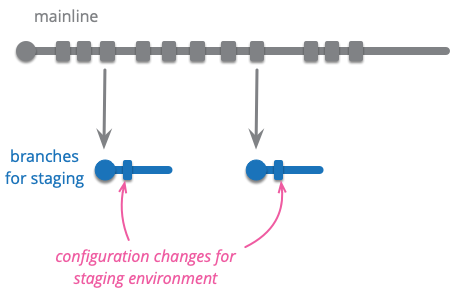
変更は通常は手作業で行われますが、担当者が git を使えるのであれば以前のブランチから変更をチェリーピックしてくることもできます。
環境ブランチのパターンは、しばしば成熟度ブランチと組み合わされます。長く続く QA の成熟度ブランチには、QA 環境向けの設定の変更が含まれているかもしれません。このブランチへのマージは、設定の変更を使うことになります。同様に、長く続くリリースブランチにも、これらの設定変更が含まれているかもしれません。
いつ使うべきか
環境ブランチは魅力的なアプローチです。これにより、新しい環境に対応するために必要な微調整をアプリケーションに施すことができます。これらの変更は diff で見ることができるので、将来のバージョンでチェリーピックすることもできます。しかし、これはアンチパターンの典型的な例であり、始めたときは魅力的に見えても、すぐに不幸、ドラゴン、コロナウイルスの世界につながってしまいます。
環境の変化に伴う危険は、アプリケーションをある環境から別の環境に移動させたときにアプリケーションの動作が変化したときに生じます。本番環境で動作しているバージョンを開発者のワークステーションでデバッグすることができなければ、問題を修正するのがはるかに困難になります。特定の環境でのみ現れるバグが混入することもあるでしょうが、最も危険なのは本番環境です。このような危険性があるため、可能な限り本番環境でも他の場所で実行するのと同じコードが実行されるようにしたいものです。
環境ブランチの問題は、それを魅力的なものにしている柔軟性にこそあります。環境ブランチではコードのあらゆる側面を変更することができるので、設定パッチを簡単に導入することができ、それによって環境ごとの挙動の違いやバグを引き起こすのです。
その結果多くの組織では、一度コンパイルされた実行ファイルはどの環境でもその同じ実行ファイルを使わなければならないと賢明にも主張しています。設定変更が必要な場合は、明示的な設定ファイルや環境変数のような仕組みで隔離しなければなりません。そうすれば、実行中に変更されない定数を設定するだけで済むので、バグが入り込む余地が少なくなります。
ソースを直接実行するソフトウェア(JavaScript、Python、Ruby など)では、実行ファイルと設定ファイルの間の単純な区分けは非常に曖昧になりがちですが、同じ原則が成り立ちます。環境の変更は最小限にとどめ、環境毎の差異を保持するのにブランチを使わないようにしてください。一般的な経験則としては、製品のどのバージョンをチェックアウトしても、どのような環境でも実行できるようにすべきであるということです。つまり、デプロイする環境ごとの差異はソースコントロールの管理化に置くべきではないということです。デフォルトのパラメータの組み合わせをソースコントロールに保存することには議論がありますが、アプリケーションの各バージョンは、環境変数のような動的な仕組みを使って、必要に応じてこれらの異なる設定を切り替えることができるようにすべきです。
環境ブランチは、貧者のためのモジュラーアーキテクチャとしてソースブランチを使用する一例です。アプリケーションが異なる環境で動作する必要がある場合、異なる環境間での切り替え機能は、その設計の第一級のパーツである必要があります。環境ブランチは、その設計に欠けているアプリケーションのための一時しのぎのメカニズムとしては有用ですが、持続可能な代替案を用いて将来的には削除するべきです。
✣✣✣
✣ ホットフィックスブランチ ✣
本番環境の緊急の欠陥を直す作業を行うためのブランチ
本番環境で深刻なバグが発生した場合は、できるだけ早く修正する必要があります。このバグに対する作業は、チームが行っている他の作業よりも優先度が高いものとし、このホットフィックスの作業を遅らせるような作業は行わないようにする必要があります。
ホットフィックスの作業はソースコントロール上で行うことでチームが適切に記録し、共同作業ができるようになります。これは、最新のリリースされたバージョンからブランチを切り、そのブランチ上で修正を行うことで実現できます。
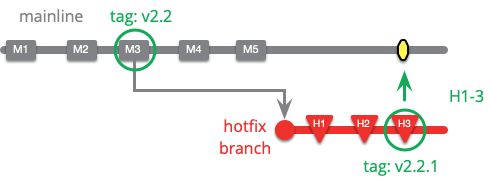
本番環境に修正を適用し、全員が一晩寝る時間を確保したら、次のバージョンでリグレッションが発生しないようにメインラインに修正を適用します。次のバージョンのためのリリースブランチがある場合は、そのブランチにもホットフィックスを適用する必要があります。リリースからリリースまでの期間が長い場合は、変更されたコードの上にホットフィックスを適用するケースも多くなるので、マージするのが面倒になります。このような場合には、修正したバグを再現する良いテストがとても役に立ちます。
チームがリリースブランチを使用している場合、ホットフィックスの作業をリリースブランチで行い、完了したら新しいリリースを行うこともできます。本質的には、これは古いリリースブランチをホットフィックスブランチとして使っていることになります。
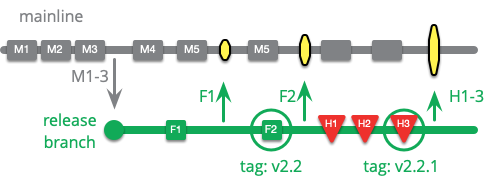
リリースブランチと同じように、メインライン上でホットフィックスを作成して、リリースブランチにチェリーピックすることは可能です。しかし、ホットフィックスは通常強い時間的なプレッシャーの中で行われるので、このやり方はあまり一般的ではありません。
継続的デリバリーを行っているチームであれば、メインラインから直接ホットフィックスをリリースすることができます。この場合もホットフィックスブランチを使うことはできますが、最後にリリースされたコミットからではなく、最新のコミットからブランチを切ります。
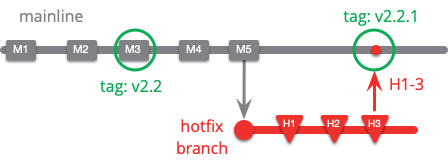
私は新しいリリースを 2.2.1 としました。チームがこのような作業をしている場合、M4 や M5 では新機能が追加されていないだろうからです。もし新機能が追加されていたら、ホットフィックスは 2.3 のリリースに組み込まれることになるでしょう。これはもちろん、継続的デリバリーでは、ホットフィックスは通常のリリースプロセスから逸脱する必要がないことを示しています。チームが十分に対応できるリリースプロセスを持っていれば、ホットフィックスは通常のリリースプロセスと同じように処理することができます。そして、これが継続的デリバリーのマインドセットの中でも特に重要な利点なのです。
継続的デリバリーを実践しているチームでも特別にやるべきことがあるとすると、ホットフィックスが完了するまでメインラインへのコミットを一切禁止することが挙げられます。これは、メインラインの修正よりも重要なタスクはないという真言に合致しています。そしてこれはメインラインで発見されたすべての欠陥、本番にまだ適用されていないものも含めて、に当てはまります。(なので、これも特別な扱いではないと思います)。
いつ使うべきか
ホットフィックスは通常かなりのプレッシャーがかかる状況で行われ、チームが最もプレッシャーにさらされている時はミスをする可能性が高いです。このような状況下では、ソースコントロールを使って頻繁にコミットすることは、通常よりもさらに価値のあることです。この作業をブランチ上に保持することで、問題に対処するために何が行われているのかを誰もが知ることができます。唯一の例外は、メインラインに直接適用できる単純な修正を行う場合です。
ここでより興味深い問題として、どれが修正すべきホットなバグでありどれが通常の開発ワークフローで修正するべきなのかという点があります。チームがリリースを頻繁に行えば行うほど、本番のバグ修正を通常の開発のリズムで行うことができるようになります。ほとんどの場合、その決定は主にバグのビジネスへの影響と、それがチームのリリース頻度に合致しているかどうかに依存します。
✣✣✣
✣ リリーストレイン ✣
定期的に発車する列車のように、設定された時間間隔でリリースを行う。 開発者は、機能を完成させたときにどの列車に乗車するかを選択する。
リリーストレインを使用するチームは、2 週間ごとや半年ごとなど、定期的なリリースのスケジュールを設定します。列車のスケジュールのメタファーに倣って、チームが各リリースのためにリリースブランチを切る日付が設定されます。チームはある機能をどの列車に乗せたいか決め、その列車に向けて作業を行い、列車が乗車待ちの間に適切なブランチにコミットします。列車が出発すると、そのブランチはリリースブランチとなり、修正のみを受け入れます。
毎月の列車を発車させているチームは、2 月のリリースを元に 3 月のブランチを開始します。彼らは月を追うごとに新しい機能を追加していきます。決められた日、例えばその月の第三水曜日に列車が出発し、そのブランチの機能開発は凍結されます。彼らは 4 月の列車のために新しいブランチを開始し、そこに新しい機能を追加します。その間、何人の開発者が 3 月の列車を安定させ、準備ができたら本番にリリースします。3 月の列車に適用された修正はすべて 4 月の列車にチェリーピックされます。
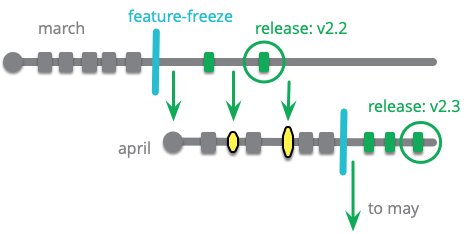
リリーストレインは通常フィーチャーブランチと一緒に使用されます。スカーレットが自分のフィーチャがいつ終了するか目処がついたら、彼女はどの列車に乗るかを決めます。もしスカーレットが 3 月のリリースまでに間に合うと思えば、3 月の列車にインテグレーションしますが、そうでなければ次の列車を待ってそこにインテグレーションします。
一部のチームでは、列車が出発する(こちらはハードフリーズです)数日前にソフトフリーズを行うこともあります。いったんリリース列車がソフトフリーズ状態になったら、開発者は機能が安定していてリリースの準備ができているという確信がない限り、その列車に作業を入れてはいけません。ソフトフリーズ後に追加された機能にバグが合った場合、列車上で修正されるのではなく、リバート (列車から押し出される) されます。
最近では「リリーストレイン」と聞くと、SAFe の「アジャイルリリーストレイン」という概念を思い浮かべる人もいるかもしれません。SAFe のアジャイルリリーストレインとは、リリーストレインのスケジュールを共有する複数のチームからなる大規模なチームのことを指し、チームの組織構造のことを指しています。リリーストレインのパターンを使っていますが、私がここで説明しているようなものと同じではありません。
いつ使うべきか
リリーストレインパターンの中心的なコンセプトは、リリースプロセスの規則性です。リリース列車がいつ出発するかを事前に知っていれば、その列車のために機能を完成させる計画を立てることができます。もし、3 月の列車に機能を完成させることができないと思うなら、次の列車に乗せようと判断できます。
リリーストレインは、リリースプロセスに大きな摩擦がある場合に特に有効です。リリースの検証に数週間かかる外部のテストグループを利用している場合や、製品の新バージョンが出る前にリリース委員会で合意が必要な場合などです。このような場合は、リリースの摩擦を取り除き、より頻繁にリリースできるようにした方が賢明な場合が多いです。もちろん、モバイルデバイスのアプリストアで使用される検証プロセスのように、これが不可能に近い状況もあります。このようなリリースの摩擦に合わせてリリーストレインをチューニングすることで、その状況に最適化することができるかもしれません。
リリーストレインのメカニズムは、どの機能がいつ搭載されるべきかに全員の注意を集中させ、いつ機能が完成するかの予測可能性を高めるのに役立ちます。
このアプローチの明らかな欠点は、列車の期間の早い段階で完成した機能が出発を待っている間待ちぼうけを食らうという点です。もしこれらの機能が重要なものであれば、それは製品が数週間から数ヶ月間、重要な機能を見逃してしまうことを意味します。
リリーストレインは、チームのリリースプロセスを改善するための貴重なステップになります。チームが安定したリリースを行うことが難しい場合、継続的デリバリーにいきなり飛びつくのはやりすぎです。まずはリリーストレインを使ってみるというのは、難しいですが筋の通った最初の良いステップになります。チームがスキルを身につけるにつれて列車の頻度を増やしていくことができ、最終的にはチームの能力が向上していくにつれて継続的デリバリーを実現するためにリリーストレインを辞める事ができます。
派生: 未来の列車への乗車
フィーチャートレインの基本的な例では、前の列車が出発するのと同時に新しい列車がプラットフォームに到着して機能を乗せていくというものです。しかし、別のアプローチとして、複数の列車が同時にフィーチャを受け入れるようにすることもできます。スカーレットが 3 月の列車で自分のフィーチャーが完成しないと思った場合でも、ほとんど完成したフィーチャーを 4 月の列車にプッシュし、それが出発する前にフィーチャーを完成させることができます。
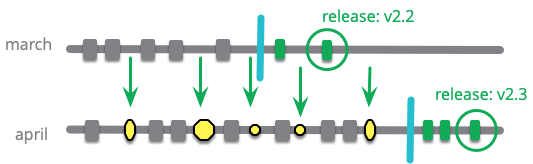
一定の間隔で 3 月の列車から 4 月の列車にプルします。3 月の列車が出発したときにだけプルすることでマージを一度で済ませるやり方を好むチームもありますが、小さなマージの方が指数関数的に簡単であることを知っている人は、できるだけ早く 3 月の列車に行われた各コミットをプルするやり方を好むでしょう。
未来の列車で乗車を待ち受けることで、4 月の機能に取り組んでいる開発者は、3 月の列車での作業を邪魔することなく共同作業を行うことができます。これは、4 月の作業が 3 月の作業と衝突するような変更を行った場合、3 月の作業をしている人はフィードバックを得られず、将来のマージをより複雑にしてしまうという欠点があります。
メインラインからの通常リリースとの比較
リリーストレインの主な利点の一つは、本番環境へのリリースが定期的に行われることです。しかし、新しい開発のために複数のブランチを持つことは複雑さを増します。もし定期的なリリースを行うことが目的であるならば、メインラインを使っても同様にこれを達成することができます。リリーススケジュールを決定し、そのスケジュールのタイミングでメインラインの先頭からリリースブランチを切ります。
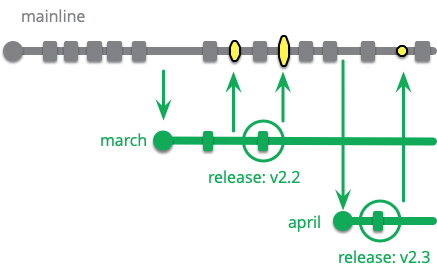
リリース可能なメインラインであれば、リリースブランチの必要はありません。このような定期的なリリースでは、開発者はほぼ完成した機能を次のリリースに向けて保留するために、定期的なリリース日の直前であればメインラインにプッシュしないことができます。継続的インテグレーションでは、機能を次のリリースまで待たせたい場合は、キーストーンの設置を遅らせたり、機能フラグをオフにしておくことができます。
✣✣✣
✣ リリース可能なメインライン ✣
メインラインの先頭が常に本番にデプロイできるように、メインラインを十分に健全に保つ
この節の冒頭で、メインラインを健全なブランチに保ち十分なヘルスチェックを行えば、好きなときにいつでもメインラインから直接リリースして、タグによってリリースを記録する事ができると書きました。
私はこのシンプルなメカニズムの代替となるパターンを記述するのに多くの時間を費やしてきたので、今回はこのパターンにスポットを当てようと思います。なぜなら、このパターンはもし実践できれば素晴らしい選択肢となるからです。
メインラインでのすべてのコミットがリリース可能だからといって、それらすべてをリリースするべきだとは限りません。これが継続的デリバリーと継続的デプロイメントの微妙な違いです。継続的デプロイメントを実践しているチームは、メインラインに受け入れられたすべての変更をリリースしますが、継続的デリバリーではすべての変更はリリース可能ですが、リリースするかどうかはビジネス上の決定事項です(このため継続的デプロイメントは継続的デリバリーのサブセットです)。継続的デリバリーは、いつでもリリースできる選択肢を与えてくれるものと考えることができますが、そのオプションを行使するかどうかの判断はより大きな問題に依存します。
いつ使うべきか
継続的デリバリーの一部として継続的インテグレーションを組み合わせることで、リリース可能なメインラインは生産性の高いチームの共通の特徴となっています。このことと、継続的デリバリーに対する私の熱意はよく知られているので、皆さんは私の主張はこれまでに説明してきたパターンよりもリリース可能なメインラインの方が常に優れた選択肢であるというものだろうと思っているかもしれません。
しかし、パターンというものは常にコンテキストに依存します。あるコンテキストでは優れているパターンが、別のコンテキストでは落とし穴にはまることもあります。リリース可能なメインラインの有効性はチームのインテグレーションの頻度によって決まります。もしチームがフィーチャーブランチを使っていて、通常は新機能を月に一度しかインテグレーションしない場合、そのチームはあまり良い状態ではなく、リリース可能なメインラインに固執することは改善の妨げとなる可能性があります。あまり良い状態ではないというのは、アイデアから本番へのデプロイまでのサイクルタイムが長すぎるため、変化する製品へのニーズに対応する事ができないことです。また、それぞれの機能が大きいために複雑なマージや検証が必要となり、多くの衝突が発生する可能性があります。これらはインテグレーション時に現れるかもしれませんし、メインラインからフィーチャーブランチにプルするときに開発者の負担になるかもしれません。このような状況はリファクタリングの妨げとなり、モジュール性を下げ、問題を悪化させます。
この罠から抜け出すための鍵は、インテグレーションの頻度をあげることですが、多くの場合リリース可能なメインラインを維持しながらインテグレーションの頻度をあげるのは難しいでしょう。このような場合、リリース可能なメインラインを諦め、より頻繁なインテグレーションを促しリリースブランチを使って本番のためのメインラインを安定させたほうが良い場合が多いです。もちろん時間が経てば、デプロイメントパイプラインを改善することで、リリースブランチの必要性がなくなることを期待しています。
高頻度なインテグレーションという文脈では、リリース可能なメインラインはシンプルであるという明白な利点を持っています。これまで説明してきた様々なブランチの複雑さに悩まされることはありません。ホットフィックスでさえ、メインラインに適用してから本番に適用することができるので、もはや名前をつけるに値するほど特別な行為でもなくなります。
さらに、メインラインをリリース可能な状態にしておくことは、価値ある規律を奨励します。本番への準備ができているかどうかという観点を開発者の頭の中に維持し、バグや製品のサイクルタイムを遅らせるプロセス上の問題がシステムに徐々に忍び寄ることがないようにすることができます。継続的デリバリーの完全な規律 - 開発者がメインラインを壊さずに 1 日に何度もインテグレーションすること - は、多くの人にとって非常に難しい事のように思われます。しかし、一度達成され習慣化されると、チームのストレスが驚くほど減少し、比較的簡単に維持することができることに気づきます。これが、常にデリバリー可能であるという点が Agile Fluency® Model のデリバリーゾーンの重要な要素である理由です。
✣✣✣
その他のブランチパターン
この記事の主な趣旨はチームにおけるインテグレーションと本番への道のりを中心としたパターンについて議論することです。しかし、他にもいくつかのパターンについて言及したいと思います。
✣ 実験的ブランチ ✣
製品にマージされる事を期待されていない、コードベース上の実験的な作業を行う場所
実験的ブランチは、メインラインへのインテグレーションをする想定ではないアイデアを試す場所です。例えば、すでに使っているライブラリの代わりになりそうな新しいライブラリを試すようなケースかもしれません。ライブラリを置き換えるかどうかの判断を助けるために、ブランチを立ち上げ、それを使ってシステムの関連部分を書いてみたり、書き換えてみたりします。その目的は、コードベースにコードを貢献することではなく、特定の文脈において新しいツールが適用可能かどうかを学ぶことです。これは一人でやることもありますし、何人かの同僚と一緒にやることもあります。
同様に、実装すべき新機能へのアプローチがいくつかの方法がある場合もあります。それぞれの選択肢のどれを採用するかを決めるために数日を費やします。
ここでの重要なポイントは、実験的ブランチのコードは放棄され、メインラインにマージされないことを期待しているということです。これは絶対的なものではありません - 結果が気に入ってコードを簡単にインテグレーションできた場合、その機会を無視することはありません - しかし、そうなると期待している訳ではありません。普段なら必ずやっていることを省いて、テストを減らし、コードをきれいにリファクタリングしようとするのではなく重複したコードを書くかもしれません。もし実験の結果が好ましいものだったら、そのアイデアを本番のコードに適用するためにゼロから作業をやり直す事を期待しています。そこでは実験的ブランチのコミットは使わずに、あくまで備忘録やガイドとして使うのです。
実験用ブランチの作業が終わったら、git でタグを追加してブランチを削除します。タグによって後で再検討したくなった時のためにコードラインを保持しておきます。ここでは”exp”から始まるタグ名などと言った明確なルールを使うと良いです。
いつ使うべきか
実験的なブランチは、何かを試してみたいが最終的にそれを使うかどうかわからないときに便利です。この方法なら、どんな奇抜なことでも好きなことを何でもできるし、自信を持って簡単に片付ける事ができます。
たまに、通常の仕事をしているつもりでいても、実際には実験的なことをしていたと気づくこともあります。そのような場合は、新しい実験的ブランチを開いて、メインの作業ブランチは最後の安定したコミットまでリセットすることができます。
✣✣✣
✣ 未来ブランチ ✣
他のアプローチでは対応できないような侵襲性の高い変更に使用される単一のブランチ
これはまれなパターンですが、継続的インテグレーションを使用しているときに時々発生します。あるチームがコードベースに広範囲の変更を加える必要がある場合、進行中の作業をインテグレーションするための通常のテクニックがうまく適用できないことがあります。このような場合には、フィーチャーブランチと似たようなことを行います。未来ブランチをカットしてメインラインからのプルのみを行い、最後までメインラインインテグレーションは行いません。
未来ブランチとフィーチャーブランチの大きな違いは、未来ブランチは 1 つしかないということで、その結果未来ブランチで作業している人たちはメインラインから外れすぎることもなく、他の分岐したブランチに対処する必要もないということです。
複数の開発者が未来ブランチで作業するかもしれませんが、その場合彼らは未来ブランチで継続的インテグレーションを行います。インテグレーションを行う際には、変更をインテグレーションする前にまずメインラインから未来ブランチにプルします。これはインテグレーションプロセスを遅くすることになりますが、未来ブランチを使用することの代償です。
いつ使うべきか
これは稀なパターンであることを強調しておきます。継続的インテグレーションを行うほとんどのチームでは、これを使用する必要がないのではないでしょうか。私は、システムのアーキテクチャに特に侵襲的な変更を加える場合に使用するのを見てきました。一般的にこれは最後の手段であり、抽象化によるブランチのような代替策が見つからない場合にのみ使用します。
未来ブランチは可能な限り短くしておくべきです。なぜならチームを分断するからです。分散したチームでのいかなる壁と同様に最低限に抑えておく必要があります。
✣✣✣
✣ コラボレーションブランチ ✣
正式なインテグレーションを行わずに、開発者がチームの他のメンバーと作業を共有するために作成されたブランチ
チームがメインラインを使用している場合、ほとんどのコラボレーションはメインラインを介して行われます。メインラインインテグレーションが行われた場合にのみ、チームの他のメンバーが何をしているかを見ることができます。
開発者は時にインテグレーションの前に自分の作業を共有したい場合があります。ブランチを開いて共同作業を行うことで、必要に応じてこれを行うことができます。ブランチはチームの共有リポジトリにプッシュしたり、共同作業者が個人のリポジトリから直接プルしたりプッシュしたりすることもできますし、共同作業を行うための短期的なリポジトリを作成することもできます。
コラボレーションブランチは通常は一時的なもので、メインラインにインテグレーションされると閉じられます。
いつ使うべきか
コラボレーションブランチは、インテグレーションの頻度が減るにつれて徐々に有用性を増していきます。長く続くフィーチャーブランチでは、チームの複数の人にとって重要なコード領域の変更を共同で行う必要がある場合に、非公式な共同作業が必要になることがよくあります。しかし、継続的インテグレーションを使用しているチームでは、自分の作業がお互いに見えない期間が短いため、コラボレーションブランチは必要ないでしょう。この場合の主な例外は実験的ブランチです。これはその定義からインテグレーションされることはありません。複数の人が一緒に実験に取り組む場合は、実験的ブランチもコラボレーションブランチにする必要があります。
✣✣✣
✣ チームインテグレーションブランチ ✣
メインラインとインテグレーションする前に、サブチームがお互いにインテグレーションできるようにする
大規模なプロジェクトでは、複数のチームが単一の論理コードベースで作業する場合があります。チームインテグレーションブランチを使用すると、プロジェクトの全メンバーがメインラインを使ってインテグレーションしなくても、チームメンバーがお互いにインテグレーションすることができます。
実質的には、チームはチームインテグレーションブランチをチーム内のメインラインとして扱い、プロジェクト全体のメインラインと同じようにインテグレーションします。これらのインテグレーションに加えて、チームはプロジェクトのメインラインとインテグレーションするための作業も行う必要があります。
いつ使うべきか
チームインテグレーションブランチを使う理由は、多くの開発者が活発に開発しているコードベースは個別のチームに分割することが理にかなっているからです。しかし、私たちはその仮定に注意しなければなりません。私はこれまで、チームの規模が大きすぎて一つのメインラインからすべての作業を行うことができないように思われるが、どうにか同じメインラインで作業をしていたチームを多く見てきました(私はこれまでに 100 人ほどの開発者からこういった話を聞きました)。
チームインテグレーションブランチのより重要な要因は、期待するインテグレーション頻度の違いです。プロジェクト全体ではフィーチャーブランチの生存期間は数週間程度を想定しているが、サブチームが継続的インテグレーションを希望している場合、そのチームはチームインテグレーションブランチを設け、それを使って継続的インテグレーションを行い、それが完了したら自分たちが取り組んでいる機能をメインラインにインテグレーションすることができます。
同様の効果は、プロジェクト全体が健全なブランチのために使用している標準とサブチームの健全さの標準の間に違いがある場合にも発揮されます。プロジェクト全体が高い水準の安定性をメインラインで維持できない場合、サブチームはより厳しい基準で作業することを選ぶかもしれません。同様に、サブチームがメインラインに見合う十分な水準のコミットを行うのに苦労している場合、そのチームではチームインテグレーションブランチを使用しメインラインに行く前にコードを安定化させるために自分たちのリリースブランチを使用することを選択するかもしれません。これは通常は好ましい状況ではありませんが、困難な状況では必要になることがあります。
またチームインテグレーションブランチは、その場その場でのコラボレーションではなく、正式なプロジェクト組織に基づくより構造化された形のコラボレーションブランチと考えることもできます。
✣✣✣
ブランチポリシー
この記事では、パターンの観点からブランチについて話してきました。なぜなら「唯一のブランチポリシー」を提唱したいからではなく、むしろ人々がブランチを使う一般的な方法を整理し、ソフトウェア開発の中で見られるさまざまな文脈の中でのトレードオフについて考えてみたかったからです。
長年にわたり、多くのブランチアプローチが説明されてきました。私はそれらがどのように機能し、どのようなときに最もよく機能するのかを理解しようとしてきましたが、私の頭の中では中途半端なパターンを通してしかそれらを評価できていませんでした。今ようやくこれらのパターンを分類しまとめたので、これらのポリシーのいくつかについて、パターンの観点から私がどのように考えているか見てみるのは役立つでしょう。
Git-flow
Git-flow は、私がこれまでに遭遇したブランチポリシーの中で最も一般的なものの一つとなりました。これは 2010 年に Vincent Driessen によって書かれたもので、git が普及してきた頃に登場したものです。git 以前の時代には、ブランチは先進的な話題として見られることが多かったのですが、Git はブランチをより魅力的なものにしてくれました。その理由のひとつにはツールの改良 (ファイルの移動をよりよく扱うようになったなど) がありますが、リポジトリをクローンすることは本質的にブランチであり、origin リポジトリにプッシュする際のマージの問題に同様の考え方を必要とするからです。
Git-flow では、単一の origin リポジトリでメインライン (「develop」と呼びます) を使用します。また、複数の開発者を調整するためにフィーチャーブランチを使います。開発者は、個人のリポジトリをコラボレーションブランチとして使用して、同じような作業をしている他の開発者との調整を行うことが推奨されています。
伝統的に git のコアとなるブランチは “master” と呼ばれますが、Git-flow では master を 本番環境用の成熟度ブランチ として使用します。Git-flow ではリリースブランチを使用して、作業は “develop” からリリースブランチを経て “master” に送られます。ホットフィックスはホットフィックスブランチを使って行われます。
Git-flow はフィーチャーブランチの長さについては何も言っていませんし、したがって、期待するインテグレーション頻度についても何も言っていません。また、メインラインを健全なブランチにすべきかどうか、もしそうならどの程度の健全性が必要なのかについても何も言っていません。リリースブランチが存在するということは、それがリリース可能なメインラインではないことを示唆しています。
Driessen が今年の補遺で指摘したように(訳注: 2020/05/05 に Git-flow のドキュメントに”Note of reflection”という形で追記された部分)、Git-flow は、顧客の環境にインストールするタイプのソフトウェアのように、複数のバージョンが本番でリリースされているプロジェクトのために設計されたものです。複数のバージョンが存在するということは、もちろんリリースブランチを使う主なきっかけのひとつです。しかし、多くのユーザーが Git-flow を使い始めたのは、本番で運用されるバージョンが一つしかないウェブアプリケーションのコンテキストであったのです。ここでは容易に必要以上にブランチの構造が複雑になります。
Git-flow は非常に人気があり、多くの人が使っていると言っていますが、Git-flow を使っていると言っている人が実際にはまったく違うことをしているのはよくあることです。多くの場合、彼らの実際のアプローチは GitHub Flow に近いものです。
GitHub Flow
Git-flow は本当に人気を博しましたが、ウェブアプリケーションで使うには必要以上にブランチ構造が複雑になるため、多くの代替案が生まれました。GitHub の人気が高まるにつれ、GitHub の開発者が使用していたブランチポリシーが、GitHub Flow と呼ばれるよく知られたポリシーになったことは驚きではありません。最もよくまとまっているのは Scott Chacon 氏によるものです。
GitHub Flow という名前から、意図して Git-flow をベースにしていて、かつそれに対する反動だとしても不思議ではありません。両者の本質的な違いは、製品の種類が違う、つまりコンテキストが違う、したがってパターンが違うということです。Git-Flow は、複数のバージョンが存在する製品を想定していました。GitHub Flow は、運用しているのはひとつのバージョンだけで、リリース可能なメインラインに高頻度でインテグレーションされていることを想定しています。このような状況では、リリースブランチ は必要ありません。本番環境での問題は通常の機能と同じように修正されるので、ホットフィックスブランチは必要ありません。というのもホットフィックスとわざわざ呼ぶからにはこれは通常のプロセスと違うことをやることを意味しているからです。これらのブランチが不要になると、メインラインブランチとフィーチャーブランチだけから成り、ブランチ構造が劇的に単純化されます。
GitHub Flow では、メインラインのことを”master”と呼んでいます。開発者はフィーチャーブランチを使って作業します。彼らは定期的にフィーチャーブランチを共有リポジトリにプッシュして作業中のコードを共有しますが、機能が完成するまではメインラインとのインテグレーションはありません。Chacon は、フィーチャーブランチは 1 行のコードになることもあれば、数週間に渡って実行されることもあると述べています。プロセスはどちらの場合でも同じように行われます。GitHub であることから、プルリクエストの仕組みは メインラインインテグレーション の一部であり、レビュー済みコミット を使用しています。
Git-flow と GitHub Flow はよく混同されるので、これまで似たようなケースがありましたが、名前に惑わされるのではなくそれぞれの flow で何が行われているのか起こっているのかを本当に理解しましょう。両者の一般的なテーマは、メインラインブランチとフィーチャーブランチをどう使うかということです。
トランクベース開発
先ほども書きましたが、「トランク駆動開発」という言葉を継続的インテグレーションの代名詞として使われることを耳にすることがほとんどです。しかし、Git-flow や GitHub Flow に代わるブランチポリシーとしてトランク駆動開発を捉えるのも一理あります。Paul Hammant 氏は、このアプローチを説明するための詳細をウェブサイトに書いています。Paul は ThoughtWorks の長年の私の同僚で、クライアントの凝り固まったブランチ構造に大鉈を振るってきた確かな実績を持っています。
トランクベース開発では、すべての作業をメインライン(「トランク」と呼ばれ、「メインライン」の一般的な同義語)上で行うことに焦点を当てているため、生存期間の長いブランチを避けることができます。小規模なチームではメインラインインテグレーション使ってメインラインに直接コミットしますが、大規模なチームでは、生存期間が数日以内のフィーチャーブランチを使うこともあります。これは実質的には継続的インテグレーションに相当します。チームは、リリースブランチ(「リリースのためのブランチ」と呼ばれる)やリリース可能なメインライン(「トランクからのリリース」と呼ばれる)を使用することもできます。
最終的な感想とおすすめ
初期のプログラムの頃から、既存のプログラムを少し修正するだけであれば、ソースをコピーして修正することで簡単に実践できるということが、人々にはわかっていました。すべてのソースがあるので、私はいかなる変更も行うことができます。しかしこの行為によって、私のコピーを元のソースの新機能やバグ修正として受け入れるのを難しくもしています。多くの企業が初期の COBOL プログラムで発見し、今日の広範囲にカスタマイズされた ERP パッケージで苦しんでいるように、時間の経過とともに、それは不可能になる可能性があります。たとえバージョン管理システムを使っておらずそう呼ばれていなくても、ソースコードをコピーして修正するときはいつでも、ソースブランチを行っていることになります。
この長い記事の最初に言ったように:ブランチは簡単ですが、マージは難しいです。ブランチは強力なテクニックですが、goto 文やグローバル変数、並行処理のためのロックを思い浮かべてしまいます。強力で使いやすい反面、容易にやりすぎてしまい不注意な人や経験の浅い人にとってはトラップになってしまうことがよくあります。ソースコード管理システムは、変更を追跡することでブランチを制御するのに役立ちますが、最終的には問題が発生していることを可視化するだけです。
私はブランチが悪だと言っている訳ではありません。1 つのコードベースに複数の開発者が貢献しているような場合だと、賢明なブランチの利用が必要となるケースはあります。しかし、私たちは常にそれに注意し、有益な薬と毒の違いは用量であるというパラケルススの観察を思い出すべきです。
ですから、私のブランチに対する最初のヒントは、ブランチの使用を検討しているときはいつでも、どのようにマージするのかを考えましょうというものです。どのようなテクニックを使うときも、代替品とのトレードオフをしていることになります。そのテクニックのコストをすべて理解することなしに賢明な判断をすることはできません。そして、ブランチでは、マージの際にコストがかかります。
したがって、次のガイドラインはこのようになります:ブランチに代わる手段についても理解しましょう。大抵はそちらの方が優れています。Bodart の法則を思い出してください。モジュール性を改善することで問題が解決しませんか?デプロイメントパイプラインを改善できませんか?タグだけで十分ではないですか?あなたのプロセスにどのような変更を加えると、このブランチが不要になるでしょうか?実際の所、ブランチを使うことは今すぐ取り組むべきことの中では正しい道のりであることが多いのですが、同時に今後数ヶ月かけて取り組むべき深い問題の兆候なのです。大抵の場合、ブランチの必要性を取り除くことは良いことです。
LeRoy のイラストを思い出してください: ブランチは、インテグレーションせずおくと指数関数的に発散します。そこで、ブランチをどのくらいの頻度でインテグレーションするかを検討しましょう。インテグレーションの頻度を 2 倍にすることを目指してください。(ここには明らかに限界がありますが、継続的インテグレーションの領域に入っていない限りまだ限界には達していないでしょう)。インテグレーションの頻度を上げるには障壁があるでしょうが、その障壁は開発プロセスを改善するためまさに克服するべき問題である事が多いです。
マージはブランチの難しい部分であるため、マージを難しくしている原因に注意を払いましょう。プロセスの問題であることもあれば、アーキテクチャの問題であることもあります。何であれ、ストックホルム症候群に屈してはいけません。マージの問題、特に危機を引き起こすような問題は、チームの有効性を向上させるための道しるべとなります。失敗は、そこから学んでこそ価値があるということを忘れないでください。
ここで説明したパターンは、私や同僚が仕事をする中で遭遇したブランチの一般的な構成を概説したものです。これらのパターンに名前を付け、説明し、そして何よりも、どのような時に役に立つのかを説明することで、どのような時にそれらを使うべきかを評価する手助けになればと思います。どんなパターンでもそうですが、一概に良いとか悪いとは言えないことを覚えておいてください。それぞれのパターンの価値はあなたのコンテキスト次第です。ブランチポリシー (Git-flow やトランクベース開発のようなよく知られたものであれ、開発組織で生まれたものであれ) に出会ったときに、その中のパターンを理解することで、それが自分の状況に合っているかどうかを判断したり、他のパターンを混ぜて使うと便利なものがあるかどうかを判断したりする助けになればと思います。
謝辞
Badri Janakiraman、Dave Farley、James Shore、Kent Beck、Kevin Yeung、Marcos Brizeno、Paul Hammant、Pete Hodgson、Tim Cochran がこの記事の草稿を読んでくれて、改善のためのフィードバックをくれました。
ピーター・ベッカーは、フォークもブランチの一形態であることを指摘するように思い出させてくれました。メインラインという名前は、Steve Berczuk 氏のSoftware Configuration Management Patternsから取ったものです。
更に知りたい方へ
ブランチについて書かれた資料はたくさんありますが、私はそのすべてを真面目に調査できる立場にはありません。しかし、Steve Berczuk の本、Software Configuration Management Patternsは注目に値します。Steve 氏の著作は、彼の貢献者である Brad Appleton 氏の著作とともに、私がソースコード管理についてどのように考えるかに大きな影響を与えています。
Originally translated by @yuichielectric