言語ワークベンチ
以下の文章は、Martin Fowler による 「Language Workbenches: The Killer-App for Domain Specific Languages?」の日本語訳である。
ソフトウェア開発における新しい考えの多くは、実は古い考えの新しい組み合わせ方です。この記事では、その新しい組み合わせ方のひとつ、私が「言語ワークベンチ(Language Workbenches)」と呼んでいるツールについて説明します。これは、現在広まりつつある考え方で、たとえば、Intentional Software、JetBrainsのMeta Programming System、MicrosoftのSoftware Factoriesなどが例として挙げられます。これらのツールは古い開発スタイルを採用しており、私はこれを「言語指向プログラミング(language oriented programming)」と呼んでいます。さらにIDEを使うことで、言語指向プログラミングを実行可能な手法にしようとしています。これらのツールが成功するかどうかを予言することは私にはできませんが、現在のソフトウェア開発における最も面白いもののひとつであると思っています。これらがどう動くのか、そして今後どのように使われるかにあたっての主要な論点、これらを(概要だけでも)説明したいと思います。これは記事を書きたいと思うほど面白いテーマなのです。
最終更新日: 2005年6月12日
ドメイン特化言語(domain specific language)を使用してソフトウェアを記述しようという開発スタイルは、以前から存在していました。 lexやyaccでコードを生成するUnix伝統の「リトル言語」、マクロを使って言語の内部に言語を構築する「Lisp」を目にすることがあるでしょう。 こういった手法は、支持者たちから非常に好まれています。 ただ、その考え方は、支持者の数ほど広まってはいません。
ここ数年、新しい種類のソフトウェア ツールを使い、このような開発スタイルをサポートする試みがありました。 最も古く、最もよく知られているものは、Intentional Programmingです。 これは元々、Charles SimonyiがMicrosoft在籍中に開発したものです。 同様のことを行った人間は他にもおり、 その勢いはこの手法への関心を一気に集めるほどです。
ここでは、この記事で使用する用語を定義します。 この分野にはまだ標準的な用語はありませんので、ここで使った用語が他のところで同じ意味として使われるとは限りません。 用語には簡潔な説明をつけています。後から詳しく説明しますので、すぐに用語を理解できなくとも心配ありません。
この記事のために作成した用語は主に2つです。 「言語指向プログラミング(Language Oriented Programming)」と「言語ワークベンチ(Language Workbench)」です。 言語指向プログラミングとは、ドメイン特化言語を使ってソフトウェア構築を行う一般的な開発スタイルのことです。 言語ワークベンチとは、このような新しい種類のツールの総称です。 つまり、言語ワークベンチは、言語指向プログラミングを行うためのひとつの方法になります。 「ドメイン特化言語(通常「DSL」と略される)」という言葉を聞きなれない方もいらっしゃるかもしれません。 これは、ある種の問題に特化して設計された限定的なコンピュータ言語のことです。 DSLを問題ドメインにのみ使用するコミュニティもありますが、私はどんなドメインに対してもDSLを使用します。
まず、現在の言語指向プログラミングの世界について、例、種類の概要、手法の長所と短所に関する意見などを交えつつ、簡単に説明したいと思います。 言語指向プログラミングに精通していれば、この部分はスキップしてください。 ただ、多くの……いや、ほとんどの開発者はこの考えに精通していないと思います。 これらを一度説明した後で、言語ワークベンチがどんなものなのか、 また、これによりトレードオフがどう変化するかについて説明します。
記事を書いていくうちに、ひとつの記事にするには内容が多すぎることが分かりましたので、いくつかの議題を他の記事に分けました。 どこでそれを読めばいいのかは、文中で説明します。 各記事ページへのリンクは、コンテンツの下にあります。 特にMPSを使った例には注目してください。 現行の言語ワークベンチを使ったDSL構築の例を示していますので、 おそらく言語ワークベンチがどういったものかが一番よく分かると思います。 そのためにも、ここで言語ワークベンチの一般的な説明について読んでから、先を進むとよいでしょう。
言語指向プログラミングの簡単な例
はじめに、言語指向プログラミングの例と、それを使用する状況とをあわせて見ていきたいと思います。 ファイルを読み込むシステムがあるとします。 このシステムはファイルを基にオブジェクトを作成します。 ファイルフォーマットは1行につき1オブジェクトとなっています。 各行はそれぞれ別々のクラスにマッピングされます。 クラスは行頭の4文字のコードで識別されます。 残りのデータはクラスのフィールドになります。 このデータは扱うクラスによって異なります。 フィールドはデリミタではなく、場所によって指し示されます。 たとえば、顧客ID番号は4文字目から8文字目にある、といった具合です。
以下がサンプルデータです。
#123456789012345678901234567890123456789012345678901234567890
SVCLFOWLER 10101MS0120050313.........................
SVCLHOHPE 10201DX0320050315........................
SVCLTWO x10301MRP220050329..............................
USGE10301TWO x50214..7050329...............................
ドットには何らかのデータが入っていると思ってください。 1行目のコメントは文字位置を見やすくするためのものです。 行頭からの4文字はデータの種類を表しています――SVCLは「service call」、USGEはレコードの「usage」です。 それに続く文字は、オブジェクトのデータです。 service callの5文字目から18文字目にある文字列は1、顧客名を表しています。
このデータをオブジェクトに変換するのにそれぞれ別々のコードを書きたくなるかもしれませんが、これからはreaderクラスを作ってタスクを単純化するようになってください。 readerクラスは、各クラスのフィールドの詳細を使ってパラメータ化することができます。
以下に簡単なreaderクラスを用意しました。readerクラスはファイルを読み込みます。 readerクラスはreader strategyクラスのコレクションを使ってパラメータ化できます――各ターゲットクラスごとにreader strategyクラスが存在します。 この例ですと、service callにひとつ、usageにひとつのstrategyが必要となります。 ここではコード(SVCL、USGE)をキーにしたMapでstrategyを保持しています。
以下がファイルを処理するコードです。
class Reader...
public IList Process(StreamReader input) {
IList result = new ArrayList();
string line;
while ((line = input.ReadLine()) != null)
ProcessLine(line, result);
return result;
}
private void ProcessLine(string line, IList result) {
if (isBlank(line)) return;
if (isComment(line)) return;
string typeCode = GetTypeCode(line);
IReaderStrategy strategy = (IReaderStrategy)_strategies[typeCode];
if (null == strategy)
throw new Exception("Unable to find strategy");
result.Add(strategy.Process(line));
}
private static bool isComment(string line) {
return line[0] == '#';
}
private static bool isBlank(string line) {
return line == "";
}
private string GetTypeCode(string line) {
return line.Substring(0,4);
}
IDictionary _strategies = new Hashtable();
public void AddStrategy(IReaderStrategy arg) {
_strategies[arg.Code] = arg;
}
ここでは行をループし、該当箇所を読み込み、どのstrategyを呼び出せばよいかを判断して、各strategyに処理を任せています。 こうした処理を行わせるには、新しいreaderクラスをインスタンス化し、strategyを読み込ませ、処理したいファイルと分離しておきます。
strategyクラスもパラメータ化できます。必要なstrategyクラスは1つです。 strategyクラスをインスタンス化する際に、コード、ターゲットクラス、およびインプットされた文字位置がクラスのどのフィールドにマッピングされるかという情報を使ってパラメータ化します。文字の情報は、field extractorクラスのリストに保持します。
class ReaderStrategy...
private string _code;
private Type _target;
private IList extractors = new ArrayList();
public ReaderStrategy(string code, Type target) {
_code = code;
this._target = target;
}
public string Code {
get { return _code; }
}
strategyをインスタンス化した後で、field extractorを追加します。
class ReaderStrategy...
public void AddFieldExtractor(int begin, int end, string target) {
if (!targetPropertyNames().Contains(target))
throw new NoFieldInTargetException(target, _target.FullName);
extractors.Add(new FieldExtractor(begin, end, target));
}
private IList targetPropertyNames() {
IList result = new ArrayList();
foreach (PropertyInfo p in _target.GetProperties())
result.Add(p.Name);
return result;
}
strategyはターゲットクラスを生成し、extractorを使ってフィールドデータを読み込み、行を処理します。
class ReaderStrategy...
public object Process(string line) {
object result = Activator.CreateInstance(_target);
foreach (FieldExtractor ex in extractors)
ex.extractField(line, result);
return result;
}
extractorは該当する行から指定されたビット部分を抜き出し、 リフレクションを使ってターゲットオブジェクトに値を埋め込んでいます。
class ReaderStrategy...
private int _begin, _end;
private string _targetPropertyName;
public FieldExtractor(int begin, int end, string target) {
_begin = begin;
_end = end;
_targetPropertyName = target;
}
public void extractField(string line, object targetObject) {
string value = line.Substring(_begin, _end - _begin + 1);
setValue(targetObject, value);
}
private void setValue(object targetObject, string value) {
PropertyInfo prop = targetObject.GetType().GetProperty(_targetPropertyName);
prop.SetValue(targetObject, value, null);
}
これまで説明したのは、非常に簡単なライブラリです。 基本的に、まず抽象的なものを作り、それを使って具体的な作業をすることになります。 抽象的なものを使うには、strategyを設定し、readerにロードする必要があります。 以下が2つのケース(service callとusage)の例です。
public void Configure(Reader target) {
target.AddStrategy(ConfigureServiceCall());
target.AddStrategy(ConfigureUsage());
}
private ReaderStrategy ConfigureServiceCall() {
ReaderStrategy result = new ReaderStrategy("SVCL", typeof (ServiceCall));
result.AddFieldExtractor(4, 18, "CustomerName");
result.AddFieldExtractor(19, 23, "CustomerID");
result.AddFieldExtractor(24, 27, "CallTypeCode");
result.AddFieldExtractor(28, 35, "DateOfCallString");
return result;
}
private ReaderStrategy ConfigureUsage() {
ReaderStrategy result = new ReaderStrategy("USGE", typeof (Usage));
result.AddFieldExtractor(4, 8, "CustomerID");
result.AddFieldExtractor(9, 22, "CustomerName");
result.AddFieldExtractor(30, 30, "Cycle");
result.AddFieldExtractor(31, 36, "ReadDate");
return result;
}
以上のコードは2つのスタイルに分かれています。 readerクラスとstrategyクラスは抽象的なコードです。 一方、最後のコードは具体的なコードです。 こうしたライブラリ クラスを構築する際は、 抽象的な部分と具体的な部分の2つに分けて考えるとよいでしょう。 抽象的な部分は、クラスライブラリやフレームワーク、関数呼び出しなどになります。 この部分は多くのプロジェクトで再利用可能です(再利用しなくてはならないという意味ではありません)。 設定コードは具体的な部分になります。 抽象的な部分よりシンプルで、素直なコードになっています。
設定コードは非常にシンプルですが、抽象的な部分に比べて変更されることが多くなります。 設定コードをC#から完全に切り離してしまうことがよく行われます。 XMLファイルにするのが今の流行りです。
<ReaderConfiguration>
<Mapping Code = "SVCL" TargetClass = "dsl.ServiceCall">
<Field name = "CustomerName" start = "4" end = "18"/>
<Field name = "CustomerID" start = "19" end = "23"/>
<Field name = "CallTypeCode" start = "24" end = "27"/>
<Field name = "DateOfCallString" start = "28" end = "35"/>
</Mapping>
<Mapping Code = "USGE" TargetClass = "dsl.Usage">
<Field name = "CustomerID" start = "4" end = "8"/>
<Field name = "CustomerName" start = "9" end = "22"/>
<Field name = "Cycle" start = "30" end = "30"/>
<Field name = "ReadDate" start = "31" end = "36"/>
</Mapping>
</ReaderConfiguration>
XMLはそれなりに便利ではありますが、可読性があるとはいえません。 カスタムシンタックスを使うことで、可読性を上げることができます。 たとえば、以下のような感じです。
mapping SVCL dsl.ServiceCall
4-18: CustomerName
19-23: CustomerID
24-27 : CallTypeCode
28-35 : DateOfCallString
mapping USGE dsl.Usage
4-8 : CustomerID
9-22: CustomerName
30-30: Cycle
31-36: ReadDate
この問題には慣れていると思いますので、ヘルプなしに構文を読めると思います。
最後の例で見たように、ここで紹介したのは小さなプログラミング言語です。 固定長のデータをクラスにマッピングする(だけの)プログラミング言語です。 Unixでいう「リトル言語」の典型的な例です。 マッピングするというタスクのドメイン特化言語です。
この言語はドメイン特化言語ですから、ドメイン特化言語の性質の多くを伴っています。 まず、非常に限定された目的にのみ適していることです。 固定長のレコードをクラスにマッピングすることしかできません。 結果としてDSLは非常にシンプルになります――制御構造もありません。 Turing completeですらありません。 この言語で完全なアプリケーションを書くことはできません。 できるのは、アプリケーション全体のちょっとした部分だけです。 つまり、DSLで何かを成し遂げるためには、他の言語と組み合わせなければなりません。 ただ、DSLはシンプルが故に、編集や変換が行いやすくなっています。 (DSLの長所と短所については後から詳しく述べていきます。)
XMLを見てみてください。これはDSLでしょうか? DSLですね。 XML構文ではありますが、やはりDSLです。いろんな意味で、前の例と同じDSLです。
いい機会ですから、プログラミング言語のよくある違いを紹介しておきましょう――「抽象構文」と「具象構文」との違いです。 具象構文は、目に見える構文です。 先ほどのXMLやカスタム言語ファイルは、具象構文は異なりますが、両方とも同じ構造を持っています――複数のmappingがあり、コードがあり、ターゲットクラスの名前があり、フィールドがあるわけです。 この基本的な構造が、抽象構文です。 プログラミング言語の構文を考える際、多くの開発者はこの違いを意識していません。 しかし、DSLを使う際にはこの違いが重要となります。 DSLでは、具象構文を2つ持つ言語が1つある、または、抽象構文を共有した言語が2つある、 という風に考えることができます。
この例では、具象カスタム構文を使えばいいのか、具象XML構文を使えばいいのかという設計上の問題がでてきます。 XML構文の方が多くのツールがあるのでパースしやすいとは思いますが、 ここではカスタム構文の方がパースは簡単です。 さらに(少なくともここでは)カスタム構文の方が読みやすいと思います。 ただ、いずれにしてもDSLのコアとなるトレードオフは同じです。 XML設定ファイルはすべてDSLだと言うことができます。
さて、さらに前のC#で書かれた設定コードに戻りましょう。 この設定コードはDSLでしょうか?
答えを考えながら、以下のコードを見てください。 このコードは、この問題のためのDSLでしょうか?
mapping('SVCL', ServiceCall) do
extract 4..18, 'customer_name'
extract 19..23, 'customer_ID'
extract 24..27, 'call_type_code'
extract 28..35, 'date_of_call_string'
end
mapping('USGE', Usage) do
extract 9..22, 'customer_name'
extract 4..8, 'customer_ID'
extract 30..30, 'cycle'
extract 31..36, 'read_date'
end
上のコードは、C#の設定コードと関係があります。
私の好きな言語を知っているひとは想像がつくかもしれませんが、これはRubyのコードです。
これは、C#の例とまったく同等のコードです。
カスタムDSLのように見えるかもしれませんが、
それは、押し付けがましくない構文、rangeリテラル、柔軟性のある実行時評価などといったRubyの機能のためです。
これはオブジェクトのインスタンス スコープを実行時に読み込み、評価することのできる完全な設定ファイルです。
しかもこれは、ピュアRubyなコードでもあり、mappingやextractメソッド(C#の例におけるAddStrategyやAddFieldExtractorメソッド)への呼び出しを行うことで、フレームワークと連携しています。
C#の例もRubyの例も、どちらもDSLです。 どちらの場合も、ホストとなる言語の機能のサブセットを使い、 XML構文に対してカスタム構文を作ったようなことを行っています。 つまり、DSLをホスト言語に組み込み、ホスト言語のサブセットを抽象的な言語のカスタム構文として使っているのです。 これはおそらく考え方の問題なのだと思います。 私は、言語指向プログラミングというメガネを通して、C#やRubyのコードを見ています。 これは、古くからある視点です。例えばLispプログラマは、Lispの中にDSLを作ることを昔から行っています。 こうした内部DSLのトレードオフは、外部DSLのそれとは明らかに異なります。 しかし、類似点も多々あります。(このトレードオフについては後ほど詳しく述べます。)
さて、DSLの例を紹介しましたが、これでうまく言語指向プログラミングを定義することができます。 言語指向プログラミングとは、複数のDSLを使ってシステムを記述することです。 システムの機能の一部をDSLで表すような、小さな言語指向プログラミングを使ってもいいでしょうし、 ほとんどの機能をDSLで表すような、大きな言語指向プログラミングを使ってもいいでしょう。これは段階的なものです。 言語指向プログラミングをどれくらい使っているか計測するのは、特に言語内DSLを使っている場合だと、難しいと思います。 再利用可能なコードのように、DSLを自分で書いておいて、別のDSLから使用するというのはよくやることですから。
伝統的な言語指向プログラミング
例で示したように、言語指向プログラミングは新しいものではありません。 みんな以前から言語指向プログラミングを行ってきていると思います。 したがって、言語ワークベンチがどのようなものか説明する前に、 現在使われている言語指向プログラミングを一覧しましょう。
言語指向プログラミングのスタイルには様々なものがあります。 そのいくつかをまとめるいい機会だと思います。
Unixリトル言語
最もDSL的なのは、Unix伝統のリトル言語でしょう。 これらは外部DSLシステムであり、通常、Unixにビルドインされたツールを使って変換を行います。 大学時代は私もlexやyaccを使って遊んだことがありました――同様のツールが、Unix tool-chainの標準部品となっています。 これらのツールを使えば、簡単にパーサーを作成し、リトル言語のためのコード(主にC言語)を生成することができます。 Awkはこのようなミニ言語の良い例です。
Lisp
Lispは、言語自体でDSLを直接表現する最も強力な代物です。 記号処理はlisperたちが実際に使っているだけでなく、その名前にも埋め込まれています。 記号処理にはlispの機能を使います――最小限のシンタックス、クロージャ、マクロを組み合わせてDSLツールとします。 Paul Grahamがこの開発スタイルについてよく書いています。 Smalltalkにもこの開発スタイルの伝統があります。
アクティブデータモデル(Active Data Models)
洗練されたデータモデラーに会うと、システムの変化しやすい部分をデータベース テーブルにデータとして格納する方法を教えてくれます(これは、メタデータ テーブル、テーブル駆動プログラムなどと呼ばれます)。 コードはテーブル内のデータを解釈し、振る舞いを実行します。
これは、具体的な構文がデータベース テーブルとなっているDSLです。 これらのテーブルは、通常、何らかのGUIインターフェースを使って管理されています。 アクティブデータはそこで編集することができます。 この作業を行っている人間は言語を作っているとは考えていません。 リレーショナル形式の具体的な構文を使うことは難しいため、言語は小さく、焦点が絞られたものとなります。
適応型オブジェクトモデル(Adaptive Object Models)
ハードコアなオブジェクトプログラマに話し掛けると、 彼らが構築したシステムについて教えてくれます。 そのシステムは、柔軟性のある強力な環境に組み込まれたオブジェクトの組み合わせで作られています。 そのようなシステムは、洗練されたドメインモデルで構築されています。 ドメインモデルでは、設定用のオブジェクトから振る舞いを取り出し、複雑なケースを処理しています。 OO人間は、適応型オブジェクトモデルをアクティブデータモデルの強力版として扱っています。
このような適応型モデルは内部DSLです。 これまでの経験では、一度モデルを構築して揺さぶりをかけておくと、みんな適応型モデルに慣れていき、生産性が飛躍的に向上することが分かっています。 一方のダークサイドは、このようなモデルは初めての人間には理解しづらいという点です。
XML設定ファイル
現在のJavaプロジェクトを見てみてください。 システムでは、JavaよりもXMLのほうが使われていることが分かると思います。 エンタープライズJavaシステムでは様々なフレームワークを使用します。 フレームワークの多くは複雑なXML設定ファイルを持っています。 こうした設定ファイルはDSLと呼ぶことができます。 カスタムフォーマットほど読みやすくはありませんが、XMLはパースしやすい代物です。 あの<カッコ>が目に悪いという人のために、 XMLファイルを編集するためのIDEプラグインを書くひともいます。
GUIビルダ
GUIを構築するようになってから、ドラッグ アンド ドロップでGUIをレイアウトできるようになりました。 Visual Basicが最も有名な例でしょう。 私はGUIが一般的になる遥か昔から、キャラクタ スクリーン用のスクリーン ビルダを使っていました。 こうしたツールはクローズドなフォーマットでレイアウト情報を保存し、実行に適したコードを生成します(または、必要な情報をすべてコードに含めて生成します)。 確かに見た目はキレイです。ですが、派手なデモには向いているが、限界がある、ということが次第に分かってきています。 そのため、多くのGUI開発者は複雑なアプリケーションにGUIビルダを使わなくなっています。
GUIビルダは一種のDSLです。しかし、我々が使ってきたテキスト言語とは編集方法が異なります。 そのため、GUIを構築する人からは言語と見なされないことがよくあります――これをGUIビルダの問題だと言う人もいます。
言語指向プログラミングの長所と短所
考えてみると、実に様々な形の言語指向プログラミングがポピュラーになっています。 言語指向プログラミングは大まかに2つに分けると便利だと気付きました。 「外部DSL」はアプリケーションのメイン(ホスト)言語とは異なる言語で書かれたもので、 後からコンパイラやインタプリタがメイン言語に変換します。 Unixリトル言語やアクティブデータモデル、そしてXML設定ファイルなどがこのカテゴリに含まれます。 「内部DSL」は、ホスト言語をDSLそのものに変化させたものです。Lispの伝統は、内部DSLの最良の例でしょう。
両者の違いをうまく表すことができる「対」になった言葉が存在しなかったため、 「内部」「外部」という用語をこの記事のために作成しました。 内部DSLは「組み込みDSL(embeded DSLs)」とも呼ばれますが、アプリケーションに組み込まれている言語と混同してしまうため、組み込みという用語を使いたくありませんでした(VBAは外部DSLですが、Wordに「組み込まれて」います)。 ただし、DSLについて書かれたものではよく「組み込み」という用語が使われています。
外部DSLと内部DSLはまったく異なるものですから、それぞれ別々に見ていきましょう。
外部DSL
外部DSLはアプリケーションのメイン言語とは異なる言語で書かれたものです。 先ほどの例では、最後の2つが外部DSLとなります。 Unixリトル言語やXML設定ファイルは外部DSLの良い例です。
外部DSLの長所は、好きなフォーマットを使ってよいという点です。 つまり、読み書き可能な最も簡単なフォーマットを使って、ドメインを表現することができるわけです。 設定ファイルをパースし、実行可能なもの(通常はベースとなる言語になります)を生成するトランスレータを作成できるのであれば、このフォーマットが使用できます。
トランスレータを自分で作成しなければならないということは、短所でもあります。 上記で示したようなシンプルな言語ならばそれほど難しくはありませんが、 複雑な言語になるとトランスレータの作成も難しくなります――ただし、それほど困ることでもありません。 パーサ ジェネレータやコンパイラ コンパイラ ツールを使えば、 非常に複雑な言語を操作することができます。 もちろんDSLもです。DSLは非常にシンプルなものだからです。 XMLはDSLの形式を制限していますが、それでもパースするのは簡単です。
外部DSLの最大の短所は、私が「シンボリック インテグレーション(symbolic integration)」と呼んでいるものが欠けている点です――要は、DSLがベース言語にリンクしていないのです。 ベース言語の環境は我々が行っていることを考慮してはくれません。 プログラミング環境は日に日に精巧になっているため、これはますます問題となっています。
簡単な例として、先ほどの例にあるターゲットクラスのプロパティをリネームしてみましょう。 現代のIDEでは、自動リファクタリング機能でリネームが行えますが、リネームはDSLまでは及びません。 C#の世界とファイルマッピングDSLとの間に、 私が「シンボリック バリア(symbolic barrier)」と呼んでいるものが存在するのです。 マッピングDSLをC#に変換することはできますが、 このバリアがあるために、全てのプログラムを操作することはできません。
このバリアによって、ツールに関する問題がいくつもでてきます。 そもそも、何を使ってDSLをエディットすればよいのでしょうか? テキスト エディタでも可能ですが、現代のIDEを使ってしまうと、テキスト エディタはもはや原始的な代物に見えてしまいます。 ポップアップリスト、フィールド名の補完、文字が重なってしまったときの赤い波線といった機能が欲しいものです。 しかし、この機能を実現するには、エディタが私のDSLのセマンティックスを理解できなくてはなりません。
セマンティックス エディタはなくても構いませんが、それでは、次にデバッグのことを考えてみましょう。 私のデバッガは変換されたC#であればステップインできますが、 本物のソースにステップインすることはできません。 本当に欲しいのは、私が作ったDSL用の、本格的なIDEです。 テキスト エディタとシンプルなデバッガの時代なら、 これはそれほど大きな問題ではありませんでした。 しかし、我々は「PostIntelliJ」の世界に生きているのです。
外部DSLに対する反対意見でよくあるのは「言語不協和音」問題です。 言語は習得するのが困難なため、多くの言語を使うのは難しいというのです。 これはDSLを誤解しているのでしょう。 おそらく、複数の汎用言語を想像しているのだと思います。 それだと簡単に不協和音になってしまいます。 しかし、DSLは制限されており、シンプルで、習得が簡単なのです。 これはDSLがドメインに近い存在だからです。 DSLは汎用プログラミング言語とは違います。
基本的に、ある程度のサイズのプログラムでは、抽象的な部分を複数取り扱うことになります。 たとえば、先ほどの例のファイル読み込みのようなところです。 通常、この抽象的な部分はオブジェクトとメソッドを使います。 確かにこれでも動きますが、やりたいことを表現するために制限された文法を使わなくてはなりません(どれくらい制限されるかはベースとなる言語によります)。 一方、外部DSLを使うと、操作しやすい文法にすることができます。 ここで問題となるのは、新しいDSLを理解するコストよりも、外部DSLによって操作が簡単になっている部分が大きいのかという点です。
これについては、DSLの設計の難しさが焦点となります――言語設計は難しく、どんなプロジェクトでも、複数のDSLを設計するのは難しいというわけです。 この反対意見も、DSLではなく汎用言語を前提に考えているのでしょう。 ここで焦点をあてるべきは、どれだけ良い抽象化ができるかということだと思います――これは非常に難しい作業です。 APIの設計とDSLの設計の違いさほどありません――ですから、DSL設計がAPI設計よりも格段に難しいものだとは思いません。
外部DSLが多くの人にとって非常に有益なのは、実行時に評価されるという点です。 つまり、プログラムを再コンパイルせずにパラメータを変更できるのです。 XML設定ファイルがJavaの世界でこんなにもポピュラーになったのは、このためです。 このことは、静的にコンパイルされる言語においては重要な点なのですが、 実行時に式を評価できる言語も多く存在することを覚えておきましょう。 実行時に評価できるな言語にとっては、これはさほど重要なことではありません。 .NETにおけるIronPythonのような、コンパイルタイムとランタイムを混ぜたような言語も出てきています。 IronPythonの内部DSLは、C#システムのコンテキストで評価できます。 これはUnixの世界ではよくあるテクニックで、UnixではC/C++をスクリプト言語でミックスしたりします。
内部DSL
内部DSLの長所と短所は、外部DSLのそれをひっくり返したものとなります。 まず、ベース言語とのシンボリック バリアがありません。 ベース言語のパワーと既存のツールのすべてがいつでも使えます。 Lispや適応型オブジェクトモデルが、内部DSLの例です。
内部DSLでよく問題とされるのは、中括弧({})言語(C、C++、Java、C#)と内部DSLに向いたLispのような言語との間に越えられない壁があるという点です。 内部DSLは、JavaやC#ではなく、LispやSmalltalkに適しています――実際、動的言語の支持者は主な強みとしてこの点を挙げています。 スクリプト言語の世界ではこのことが再認識されています――Rubyのメタプログラミング機能や、Railsフレームワークなどを見てください。 この問題は、多くのプログラマが動的言語をちゃんと使ったことがなく、そういった機能(およびその制限)をきちんと理解していないところからきています。
内部DSLはベース言語の構文と構造に制限されます。 動的言語だと制限による制約はそれほどありません。 LispやSmalltalkといったスクリプト言語は最小の構文を持っており、 メインストリームにいる中括弧言語よりもうまく内部DSLを動かせます。 C#とRubyの例を比べてみると、その違いがより明確になるでしょう。 クロージャやマクロのような言語機能も重要です。 こうした機能はCベースの言語には見当たりませんが、それらしき機能はあります。 Annotations(C#でいうattribute)はその良い例でしょう。 このような目的に使うには便利な機能です。
ベース言語にはツールがありますが、ベース言語はDSLがやろうとしていることを知りません――ですから、ツールはDSLを完全にはサポートしていないわけです。 テキスト エディタを使ったほうがいいのかもしれませんが、改良の余地はあります。
DSLで言語のパワーを最大限に引き出すというのは、ありがた迷惑な話です。 ベース言語に精通していれば別にいいのでしょうが、DSLの強みというのは、ベース言語の機能をすべて知らない人でもプログラミングができるという点です――これにより、ドメイン知識を直接システムに取り入れることができます。 内部DSLは、ベース言語に慣れていないとユーザーが混乱する余地が多く、素人プログラマが扱うには難しいものとなっています。
この点については、汎用プログラミング言語用ツールはかず多くあるが、DSLでは限定してツールを使う、というふうにすることができます。 必要以上に多くのツールを用意してしまうと、物事がややこしくなります。 あまり使わないのにツールの習得をしなければならないからです。 理想をいえば、仕事に必要なツールだけあればいいのですが、実際はそれ以上のツールが必要となるでしょう。 (Charles Simonyiはこの考えを自由度の概念(notion)だと書いています。)
オフィス ツールにも似たようなことがあります。 現代のワープロは使いにくいと文句を言うひとが大勢います。 ひとりの人間では使い切れないほどの多くの機能があるからです。 ただ、こうした機能は誰かに必要とされているのです。 オフィス ツールは巨大なシステムを作って、ユーザー全員を満足させているのです。 各作業に適したツールを複数使うということも考えられるでしょう。 これだと、ツールを習得するのも使うのも、どちらも簡単になります。 問題は、目的に合わせてオフィス ツールを構築すると、コストがかかってしまう点です。 これは、汎用プログラミング言語(および内部DSL)と外部DSLとのトレードオフの関係によく似ています。
内部DSLはプログラミング言語に近いため、プログラミング言語にうまくマップできないものを表すのは難しいと思います。
たとえば、エンタープライズ アプリケーションではレイヤを使うことが多いのですが、
レイヤは通常、プログラミング言語のパッケージで定義されます。そのレイヤ間の依存ルールを定義するのは難しいのです。
つまり、UIコードをMyApp.Presentationに、ドメインロジックをMyApp.Domainに入れた場合、DSLには、MyApp.DomainにあるクラスがMyAPp.Presentationにあるクラスに触れてはいけないというルールをつける機能がないのです。
これもやはり、汎用言語の限界によるものです――ただし、Smalltalkでは可能です。Smalltalkでは、メタレベルに深くアクセスできますから。
( 比較として、このような動的言語で作られたより複雑な例は面白いと思います。 私はこれ以上調査することはありませんが、誰かが引き続きやってくれることを願います。その際は、LanguageWorkbenchReadingsで紹介します。 )
素人プログラマを巻き込む
外部DSLにせよ内部DSLにせよ、「素人プログラマ(lay programmers)」を巻き込めるかどうかが常に話題になります。 素人プログラマとは、本職プログラマではないが、開発の一部としてDSLでプログラムするドメイン専門家のことを指します。 素人プログラマにプログラミングさせるというのは、昔からソフトウェアの世界では言われつづけていることで、 実際、多くの人たちが初期の高級言語(COBOLやFORTRAN)をユーザーが使うようになれば、プログラマは終焉するなどと思っていました。 私はこれをCOBOLに対する誤った認識という意味で、「COBOL推論(COBOL inference)」と呼んでいます――こうした技術は、本職のプログラマを排除するようなものでは決してないのです。
COBOL推論にも関わらず、みんなユーザーからの入力をプログラムに直接入力しようとしています。 その一つに、プログラムの簡単な部分を切り出し、その部分に限ってユーザーが安全で快適にプログラムできるようにする方法があります。 ユーザーがプログラム可能な領域をDSLにするのです。 こうしたDSLは非常に洗練されています―― MatLabは非常に複雑なDSLが動いている良い例です。 これはドメインにフォーカスしてからこそできるのです。
ユーザー プログラマブルなDSLにおける外部DSLの利点というのは、ホスト言語から余分なものをすべて排除できること、そして、ユーザーにとって明快なものを提供できるという点です。制限された構文を持つ言語の場合、この点は問題となります。 しかし、たとえ制限のないシンプルな言語であっても、内部DSLだと問題があります。 DSLのスコープ外だが言語としては正しい動作をした場合、ユーザーとってはそれが奇妙な振る舞いや暗号のようなエラーメッセージのように見えてしまい、混乱してしまうでしょう。
言語指向プログラミングの提唱者の多くは、 システムのすべてのドメインロジックがユーザーによって構築されるという 将来像を持っています。 プログラマは必要なサポートツールを作り、ユーザーにプログラムを直接編集させ、コンパイルまでさせるのです。 これはプログラマの終焉を意味するものではありません――必要な数を大幅に削減し(多くのツールは再利用可能)、昨今ソフトウェア開発において停滞気味な数々のコミュニケーション問題を解決するのです。 この素人プログラマのビジョンは、非常に魅力的です。 ただし、COBOL推論によるプログラマの終焉は、まだまだ先になりそうです。
以上のことから、素人プログラマによるプログラミングは十分に利用価値があると思います。 ただし、それが言語指向プログラミングのすべてではありません。 たとえユーザプログラマを巻き込まなくとも、良いDSLはプログラマの生産性を向上させます。 良いDSLなら、プログラマが使い、ドメイン専門家がレビューすることも可能です。
素人プログラマの議論は大きな賭けです。 ほとんどすべてをユーザープログラミングをベースにした技術が正当化されていたら、私はそれを疑うと思います。 今そのようなアプローチが成功したら、それはものすごい効果があります。 ただしそれは、プログラマの終焉だからではなく、ドメイン専門家とプログラマのコミュニケーションが改善されるからです。 コミュニケーションの欠如は、ソフトウェアプロジェクトにおける最も大きなバリケードなのです。
言語指向プログラミングにおけるトレードオフのまとめ
私にとっての言語指向プログラミングの基本的な問題は、 「DSLを使うメリット」に対する「DSLを効果的に使うための必要なサポート ツールを構築するコスト」についてです。 内部DSLを使うと、ツールコストを下げることができます。その反面、DSLを制限することになり、DSLのメリットを格段に下げてしまいます。 特に、C言語のような言語を使っているとそうなります。 一方、外部DSLを使うと、潜在的なベネフィットを得ることができます。 しかし、言語設計やトランスレータの構築、それから、プログラミングをサポートするツールを用意するなど、いろいろとコストがかかります。
これが言語指向プログラミングがあんまり流行らなかった理由だと思います。 内部DSLも外部DSLも、何かしら重大なデメリットがあるわけです。 つまり、今よりDSLを使うようになってもいいのかどうなのか、判断がつきにくいわけです。
それなら、言語ワークベンチを使うとよいでしょう。 基本的に言語ワークベンチは、外部DSLの柔軟性をセマンティック バリアなしに提供できます。 さらにいうと、現代のIDEにマッチしたツールを構築するのが簡単です。 つまり、言語指向プログラミングをより簡単に構築、サポートできるようになり、 言語指向プログラミングを不遇たらしめてきたバリアを低下させることができるのです。
今日の言語ワークベンチ
言語ワークベンチというカテゴリに属するツールについて簡単に述べたいと思います。 今から紹介するツールはすべて、まだ開発初期段階のものです。 言語ワークベンチが大規模ソフトウェア開発に用いられるには、あと数年はかかるでしょう。
Intentional Software
これらのツールのゴッドファーザーは、Intentional Programmingです。 Intentional Programmingは、Microsoft ResearchのCharles Simonyiによって開発されました。 数年前、SimonyiはMicrosoftを離れ、独立して自分の会社を設立し、Intentional Softwareを開発しています。 ベンチャーではよくあることですが、彼は開発をオープンにしていません。 ですから、Intentional Softwareについての情報が不足しており、どのように使用されるかもまだ分かっていません。
私は、わずかな時間ですが、Intentional Softwareと過ごすことがありました。 ThoughtWorksの同僚は、昨年、Intentional社と一緒に仕事をしていましたので、 私は”Intentionalカーテン”の裏側をチラ見することができました。しかし、そこで見たことを今ここで言うわけにはいきません。 でもご安心を。彼らは来年あたりから成果をオープンにしていくようです。
(用語について。Intentionalの連中は、Microsoft時代の古い成果を「Intentional Programming」と呼び、現在開発中のものを「Intentional Software」と呼んでいます。)
Meta Programming System
JetBrainsが開発したMeta Programming Systemは、Intentional Softwareよりも新しいツールです。 JetBrainsはその優れたIDEツールにより、ソフトウェア開発者の間で名声を得ています。
IDEで得た経験が言語ワークベンチにも色々と反映されています。 まず、IntelliJでの成功によりツール業界で確固たる信頼を獲得しました――技術的側面、実用的側面の両方の面においてです。 また、言語ワークベンチの可能性は、ポストIntelliJ IDEを便利にする機能と密接に結びついています。
JetBrainsは数年かけて洗練されたWebアプリケーション開発環境「Fabrique」を開発しました。 Fabriqueを開発したことにより、こうしたツールをより効率的に開発するためのプラットフォームが将来必要になってくるだろうと確信しました――この思いが、MPSの開発へとつながったのです。
MPSは、Intentional Softwareの公になった部分の影響を強く受けています。 Intentionalよりも開発期間は短いですが、JetBrainsはオープンな開発サイクルを信条としています。 MPSは、使えるところがあれば、すぐにEarly Access Programで公開されてきました。 2005年前半は、このようなスタイルでやっていくようです。
幸運にも私は、MPSのリーダーであるSergey Dmitrievと一緒に働いています。 MPSの開発はJetBrainsのマサチューセッツ オフィスで行われていますので、彼らを訪ねやすいのです。 物理的な距離の近さと、彼らのオープン性のおかげで、MPSを使った詳細な例を書くことができました(先に進むまでまだ理解できなくても大丈夫です。時が来たらまたリンクを張ります)。
Software Factories
Software Factoriesは、MicrosoftのJack GreenfieldとKeith Shortによってリードされています。 Software Factoriesにはいくつかの要素がありますが、ここでは詳細については述べません(名前がダメ過ぎということだけは言っておきましょう)。 この記事に関係する要素は、DSLです――言語指向プログラミングは、Software Factoriesでは主要な役割を担っています。
Software FactoriesチームはModel Driven Developmentのバックグラウンドを持っています。 チームには、CASEツールの開発で活躍していた人や、イギリスのオブジェクト指向コミュニティを率いていた人たちが含まれています。 ですから、Software FactoriesのDSLがグラフィカルな手法になってしまっても、別に驚くことではありません。 しかし彼らは、多くのCASEツール人間たちとは違い、セマンティクスとコード生成の制御に関心があります。
ここで私は、アプリケーションの伝統的なプログラミングを引き合いに出して述べますが、 Software FactoriesチームはDSLを開発、テスト、文書化などのような自動化できない分野に適用することに関心があります。 また、DSLを直接実行したくない状況(DSLのデプロイメントなど)をシミュレートすることも調査しています。
MicrosoftのDSLチームは数ヶ月前から、Visual Studio 2005 Team Systemの一部として、いくつかをダウンロード可能にしています。
モデル駆動アーキテクチャ(MDA)
OMGのMDAを追いかけているのであれば、言語ワークベンチについて私が述べてきたこととMDAのビジョンとの間に多くの共通点があることに気が付いたでしょう。 これは論争を起こす問題ですが、今のところは、MDAの(すべてではありませんが)いくつかのビジョンは、言語ワークベンチであると言っておきましょう。 また、MDAの上に言語ワークベンチを構築するのは、非常に脆いと思っています。 この点についてより詳細に議論するために、関連した記事を書きました。 ただし、この記事を最後まで読み終わるまで、よく理解できないかもしれません。
言語ワークベンチの要素
これらのツールはすべて異なりますが、共通した特性やよく似た部分があります。
言語ワークベンチが最も強力なのは、 プログラムの編集とコンパイルとの関係を変化させる点です。 基本的に、テキストファイルの編集からプログラムの抽象形の編集へとシフトします。 これからこのことについて説明します。
従来のプログラミングでは、エディタを使ってプログラムのテキストファイルを編集します。 次に、トランスレータを使ってコンピュータが理解できる形へと変換させ、そのテキストファイルを実行可能にします。 PythonやRubyのようなスクリプト言語の場合、この変換は実行時に行われます。 JavaやC#やCのような言語の場合は、コンパイル時に行われます。
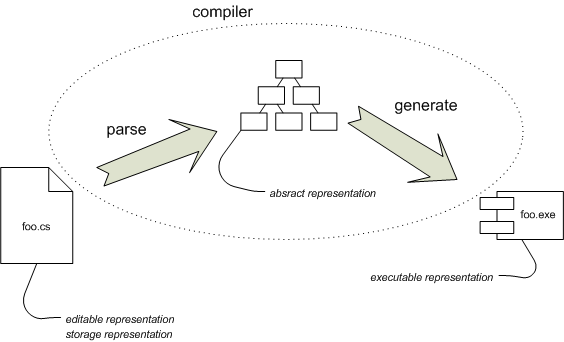
図1:伝統的なコンパイル方法
このプロセスについてもう少し詳しくお話します。 図1はコンパイル プロセスを簡単に表しています。 foo.csを実行可能にするために、コンパイラを実行しています。 ここでは話を分かりやすくするために、編集プロセスを2つのステップに分けます。 最初のステップで、テキスト ファイルであるfoo.csをパースし、抽象構文ツリー(abstract syntax tree: AST)へと変換します。 そして、次のステップで、CLRバイトコードを生成しながら構文ツリーを走査していきます。 生成されたバイトコードはアセンブリ(exeファイル)に格納されます。
■ 関連した記事をご覧下さい:Generating Code For DSLs
外部DSLからどのようにコードを生成するかについて詳しく述べています。
プログラムは様々な形を持っており、コンパイラがその形を変換していると考えることができます。 ソースファイルは編集可能形で、プログラムを変更したいときはこれを編集します。 ソースファイルは保存形でもあり、ソースコードコントロールに保存して、使いたいときに取り出して使います。 コンパイラを実行すると、まず編集可能形を抽象形(抽象構文ツリー)に変換し、それから、コードジェネレータが実行可能形(CLRバイトコード)に変換します。
(実際に実行可能な形にするには、他にもいくつかの変換が必要です。しかし、一度バイトコードにしてしまうと、コンパイラの仕事は終わり、残りの仕事はコンパイラの範疇から外れます。)
抽象形は一時的なもので、コンパイラが実行される間のみ存在します。 また、これは、編集工程を論理な2つのステップに分けるためだけに存在しています。 外部DSLとシンボリック インテグレーションを行うのが難しいのは、この変換があるためです。 各言語は別々にコンパイルを行うため、抽象形とのリンクは存在しません。 生成されたコードで初めて両者は統合されます。そのとき、抽象形はもう存在していません。
より洗練されたポストIntelliJ IDEでは、このモデルに大幅な変更を加えています。 ファイルを読み込んだとき、IDEはメモリ上に抽象形を作成します。 これは、ユーザーがファイルを編集する際に使用されます(Smalltalkも似たようなことを行っていました)。 この抽象形は、メソッド名の補完などの簡単なものから、リファクタリングのような洗練されたものまで幅広く使用されます(自動リファクタリング機能は抽象形を変換します)。
これがどれだけ凄かったのか、同僚のMatt Foemmelが述べてくれました。 こうした機能に強力にアシストされ、彼は自分がテキストを入力していなかったことに後から気付いたというのです。 テキストを入力する代わりに、抽象形にコマンドを実行していたのです。 彼の行った変更はIDEによってテキストファイルに書き戻されますが、彼が操作していたのはまさしく抽象形でした。 現代のIDEを使っていて同じような感覚を持ったことがある人なら、 言語ワークベンチがどんなものなのか、なんとなく分かることでしょう。
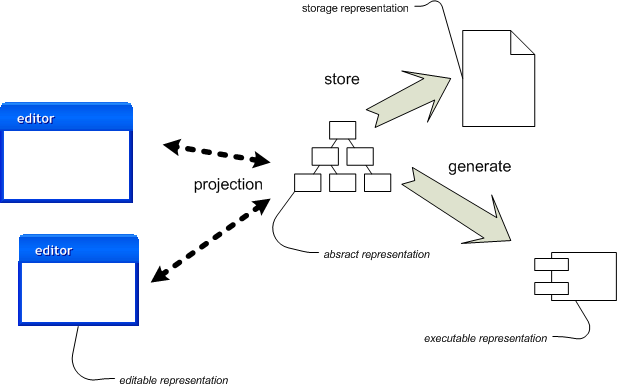
図2:言語ワークベンチを使って様々な形を操作する。
図2は、言語ワークベンチを使用した図です。 先ほどとは、「ソース」が編集可能なテキストファイルではない点が異なります。 ここでは直接、抽象形を操作します。 抽象形を編集するためには、言語ワークベンチが抽象形を何らかの編集可能な形へと投影(project)します。 この編集可能形は一時的なものです――人間を助けるためのものに過ぎません。 本当のソースは永続化された抽象形となります。
編集可能形は単に抽象形の投影に過ぎないため、何点か注意する必要があります。 最も重要なことは、編集可能形を完成させる必要がないことでしょう――差し当たり重要でないのであれば、その部分は無視することができます。 また、抽象形の投影を複数持つことができます――それぞれ、異なる側面を投影しています。 投影は言語ワークベンチの一部なので、 テキストファイルと比べると、動的に編集可能形を変化させることができます。 この投影エディタは言語と密接に結びついています。 結果としてユーザーは、エディタがどのように編集可能形を操作するのかを積極的に考えるようになります。 テキストファイルのような受身な編集可能形に比べ、 様々な考えをもたらしてくれるでしょう。
言語ワークベンチでは、保存形と編集形とを分けています。 保存形は抽象形のシリアライゼーションです。 よくやるのはXMLに保存する方法です。 ただしこのXMLは、人間が編集できるようにはデザインされていません。 XMLを保存形にすると、ツール間の互換性が高くなります。 しかし、そのような互換性は非常に難しいのが通例です。
従来ソースを実行可能形として扱う違いはありますが、 コード生成の部分は全く一緒です。 生成されるファイルは通常の言語ソースファイルと同じものですが、 これはソースではなく、直接編集できないコードです。 言語ワークベンチが成熟していくにつれ、 バイトコードのような編集できない構造を生成するほうがよいでしょう。
あまり気付かれないことですが、言語ワークベンチにとって重要なこととして、 抽象形はエラーや曖昧性に配慮すべきであるという点が挙げられます。 抽象形を操作するのであれば、常に抽象形を正常な状態にしておかなければなりません――ならば、不正確な情報をそこに入れられないようにすべきです。 しかしそれでは、ユーザビリティがひどくなってしまいます。 ポストIntelliJ IDEはこのことを認識しており、エラー状態をグラフィカルに表示するようにしています。 たとえば、コンパイルエラーのあるプログラムをリファクタリングするようなこともできます(ユーザビリティ向上のためには必要です)。
様々なソースから複雑な情報を取得するようになると、このことはより重要となってきます。 常にすべての一貫性をとり、正しく保つようなことはできません。 つまり、曖昧な状態やエラーのある状態とうまく付き合っていく必要があるのです――入力を制限するよりも、エラーを強調するのです。 また、ドキュメントのような計算不可能な情報も、モデルに簡単に入力できるようにしなければなりません。 この方法であれば、スキャニングした手書きのナプキンも、直接DSLコードにつながります。
新しいDSLの定義
このような構成にすると、 新しいDSLの定義は3つの主な部分に分けられます。
- まず、抽象構文を定義します。これは抽象形の「スキーマ」です。
- 次に「エディタ」を定義し、抽象形を投影を通じて操作可能にします。
- それから「ジェネレータ」を定義します。これは抽象形をどのように実行可能形に変換するかを定義しています。実際には、ジェネレータはDSLのセマンティクスを定義します。
これが主なトリオです。ただし、それぞれバリエーションが色々とあります。 先ほど述べたように、エディタやジェネレータを複数使っても問題ありません。 エディタが複数あることは普通のことです。 人によって編集方法の好き好きはあるものです。 例えば、Intentionalのエディタは同じモデルの異なる投影に簡単にスイッチすることができます。 ですから、階層的データ構造をLispのようなリスト形式、ネストされたボックス形式、またはツリー形式などにすることができます。
複数のジェネレータを使用するのには、いくつかの理由があります。 似たようなことを行う異なるフレームワークを構築するときに必要になることがあります。 例えば、あのイライラするSQLの方言が例として挙げられます。 他にも、パフォーマンス特性が違うとか、ライブラリ依存が違うとかで、実装のトレードオフが行われるときに必要でしょう。 3つ目の理由は、異なる言語を生成するためです。 つまり、ひとつのDSLからJavaやC#などを生成するのです。
他にも、保存形のトランスレータを定義することができます。 言語ワークベンチは抽象形を自動的にシリアライズしたデフォルト保存スキーマを使っていますが、 ツール間でやり取りするために他の保存形式を用いたり、その都度変換したりすることもできます。 この場合、通常のジェネレータとは異なり、変換は双方向に行われます。
人間が読めるドキュメントを生成するジェネレータもあります――javadocに相当する言語ワークベンチです。 言語ワークベンチとのやり取りは、ほとんどエディタ経由で行われますが、 Web文書や紙文書を生成する必要がまだあるのです。
■ 関連した記事をご覧下さい。:A Language Workbench in Action - MPS
JetBrainsのMeta-Programming Systemを使ってDSLを定義する例です。言語ワークベンチがどう動くかの具体的な例です。
言語ワークベンチの定義
現在、広く一般的に受け入れられている「言語ワークベンチ」の定義はありません。 これは別に驚くことでもありません。「言語ワワークベンチ」という言葉は、私がこの記事のために作ったものなんですから! ただ、ソフトウェアビジネスにありがちな誤用・乱用(例:コンポーネント、サービス指向アーキテクチャ)は避けたいと思いますので、言語ワークベンチの本質的特性を最初に決めたいと思います。言語ワークベンチの必要条件を以下に簡単にまとめました。
- ユーザが自由に新しい言語を定義できる。言語はそれぞれ完全に統合可能である。
- 一次情報ソースは、永続化された抽象形(persistent abstract representation)である。
- 言語設計者は、スキーマ、エディタ、ジェネレータの3つの部分に分けてDSLを定義する。
- 言語ユーザは、投影エディタ(projectional editor)でDSLを操作する。
- 言語ワークベンチは、不完全だったり矛盾だったりする情報を抽象形に永続化できる。
言語指向プログラミングのトレードオフを変える
先ほど言語指向プログラミングのトレードオフについて述べました。 言語ワークベンチにはいくつもの考慮すべき新しい点が含まれており、言語指向プログラミングのトレードオフに対して明らかに影響を与えています。
言語ワークベンチによって大きく変わったのは、外部DSLの作成が簡単になった点です。 これでもうパーサを書く必要はありません。 抽象構文を定義する必要はありますが、これは簡単なデータ モデリングで済みます。 また、DSLに使用するパワフルなIDEが手に入りました――エディタの設定に少し時間がかかりますが。 ただし、ジェネレータには手を入れなければなりません。 しかも、以前より作業が簡単になったというわけでもありません。 とはいえ、優れたシンプルなDSL用のジェネレータの構築は、最も簡単なところです。
言語ワークベンチの2番目に大きなプラスは、シンボリック インテグレーションが手に入る点です。 Excelライクな式言語を採用でき、それを専用の言語に組み込めるというのは、素晴らしいことです。 言語のシンボルを変更し、その変更をシステムすべてに反映することができるといえば、 言語ワークベンチの説得力が増します(現在できるかどうかは知りませんが)。
リファクタリングは、言語ワークベンチにおけるもっとも大きな問題です。 言語ワークベンチの使用について説明する際に 「最初にDSLを定義して、それからDSLを使って構築します。」 と言って罠にハマってしまうことは簡単なんですが、 私が以前書いたことを読んでいれば、ここに警笛を鳴らすことができるでしょう。 私は進化的設計の提唱者ですから、ここでは、DSLやDSLに組み込まれるコードも進化させる必要があります。 これは難問です。しかし、Intentionalの開発初期段階からこのことは認識されていました。 成熟した言語ワークベンチでDSLがどれだけ進化していけるかというのは、まだ分かりません――ただ、DSLが進化できないのであれば、それは言語ワークベンチの大きなマイナスとなるでしょう。
中期の視点で言語ワークベンチを見た場合、最も大きな問題はベンダー ロックインのリスクです。 スキーマ、エディタ、ジェネレータのトリオを定義する標準はありません。 言語ワークベンチで定義すると、作成した言語がその言語ワークベンチに結び付けられてしまいます。 異なる言語ワークベンチ間でやり取りするための標準もありません。 つまり、言語ワークベンチを変えると、このトリオをすべて再実装することになるのです。 DSLをやりとりするための特別な保存形を作り出すことになるかもしれません――「交換形(interchange representation)」と呼びます。 いずれにせよ、何らかの打開策がなければ、ベンダーロックインのリスクは残ります。(MDAはこの点についてベンダー非依存だと主張していますが、完全とは言えないでしょう。)
言語ワークベンチをソース生成のツールだと考えれば、問題の軽減になるかもしれません。 たとえば、JavaのXML設定ファイルをすべて管理するために言語ワークベンチを使うということが考えられます。 これならば、最悪、言語ワークベンチを捨てて、生成された設定ファイルのみを使うということもできます。 生成されたファイルの見た目がキレイになるのであれば、自分で書くよりもマシでしょう。 機能を使いこなせば、うまく構成されたJavaコードを生成することもできます。 これでリスクをある程度和らげることができます。 少なくとも、どうしようもなくなる(high and dry)という状況になることはありません。 ベンダー ロックインについては、いろいろと考える必要があるでしょう。
ツールに関してのこういった問題は、ソースファイルがテキストから移行しているために起こっています。他にも同様の問題があります――テキストではうまく解決してきた問題も、抽象形を使う際には考え直さなければなりません。 例えば、バージョン コントロールなどです。 バージョンコントロールには優れたdiff機能やマージ機能などがあり、非常に効果的です。 言語ワークベンチを効果的にするには、抽象形のためのdiff機能、マージ機能が必要となります。 理論的には、これは解決できる問題で、 リアルSemanticDiffがそれを解決してくれます( SemanticDiffでは、シンボルをリネームすると テキストを使ったときのように結果から推測するだけでなく、 「シンボルをリネームした」というふうに行為として理解してくれます)。 Intentionalはこの問題に関して、優れたソリューションを持っているようです。 しかし、まだ実際に我々が使うことはできません。
ポジティブな面に戻りましょう。 カスタム言語とエディタを組み合わせることで、 素人プログラマがDSLを編集できるようになるでしょう。 また、ユーザープログラムとコア プログラミング言語とが同期できなくなる問題については、シンボリック インテグレーションが解決してくれます。 エディタは、COBOL推論をぶち壊してくれる最も強力な唯一のツールとなります――ユーザとのやり取りにあわせてツールをカスタマイズするような場合ならばの話ですが。
ドメイン専門家と開発成果を直接つなげるというこの展望が、 言語ワークベンチにおいてもっとも興味のあるところだと思います。 我々プログラマが生産性を高めるためにツールを使ったとしても、 それは単にアイドルループを最適化しているに過ぎないということを、 何度となく経験していきています。 ほとんどのプロジェクトが見舞われる最も大きな問題は、 開発者と顧客(the business)とのコミュニケーション問題です。 コミュニケーションがうまくいきさえすれば、貧弱な技術を使ってても、進展することができます。 逆に、この関係が壊れれば、Smalltalkでもうまくいきません。
言語ワークベンチプログラミングの提唱者は、ドメイン専門家を巻き込むことについて話しています。 実際、Lispの内部DSLで楽しくプログラミングしている事務職の話を聞いたことがあります。 しかし、ほとんどの場合、こういった取り組みはうまくいっていません。 フォーカスした外部DSLを洗練されたエディタや開発環境と組み合わせれば、 もしかすると、この問題を少しは解決できるかもしれません。 そうなると、メリットは甚大です。 これによりどれだけユーザーを巻き込めるようになるかというのが、 Charles Simonyiの成果の原動力となるように思います。 彼の成果が、Intentional Softwareの決定へとつながっています。
短期の視点で見ると、このツールの限界は成熟度です。 これらのツールがリーディングエッジな開発者にヒットするまで、しばらく時間がかかるでしょう。 しかし、ご存知のように、技術は急速に変化します――ツールや言語の選択を、10年前と比べてみれば分かります。
■関連した記事をご覧ください。:Language Workbenches and Model Driven Architecture
'’OMGのMDAが言語ワークベンチとどのように関係しているのかについて述べています。’’
DSLのコンセプトを変える
この記事で使ったのはつまらない例でした。 これを使ったのは、みんなに伝えやすく、しかも作るのが簡単だったからです。 もっと複雑なものでも、DSLの動きは一緒です――ですから、伝統的なテキスト形式を使ったほうがDSLの動きを把握しやすいのです。 多くの人はグラフィカルなDSLに注目しています。 しかしそれでは、DSLの潜在能力のすべてを掴んだとは言えません。 「言語」という言葉を使う際に最も危険なのは、 言語ワークベンチでできることを見失わせてしまうことです。
同僚とOPOSLA 2004について話していたとき、最も話題になったのはJonathon EdwardsのデモによるExample Centric Programmingでした。 エディタにプログラムコードを表示するだけでなく、サンプルの実行結果もコード内に表示するのです。 それを見て、操作するのは抽象形でもよいが、考えるのは具体的なケースを使ったほうが簡単だと思いました。 サンプルを使った学習は、テスト駆動開発(TDD)の面白さでもあります――私はこれを実例による仕様だと考えています。
EdwardsはSubtextと呼ばれるツールに更なるアイデアを集約しています。 Subtextは言語ワークベンチの原則をいくつか共有しています――特にソースコードにテキストを使わないところなどがそうです。 Subtextは新しい言語の定義を簡単にすることに興味はないようですが、 言語とツールが深く絡み合った言語ワークベンチとして開発できるのではないかと思わせてくれます。
言語ワークベンチがCOBOL推論の影響を避けられるのは、言語とツールが深く絡み合っているからだと言ってもよいでしょう。 最初に言いましたが、ユーザーが素人プログラマになれるような技術には絶えず遭遇しています――ただしそれは、いつも失敗するのです。 素人プログラマが本当に生産的になるような技術は何でしょうか――そう、表計算ソフト(spreadsheets)です。
多くのプログラマは表計算ソフトがプログラミング環境だとは考えていません。 しかし、多くの素人プログラマが表計算ソフトを使って洗練されたシステムを作っています。 表計算ソフトは、素人プログラミングのツールが必要とする特徴を指し示している興味深いプログラミング環境です。例えば、
- 即時フィードバック:サンプルの計算結果をすぐに表示するなど。
- ツールと言語の密な統合
- テキストソースがない
- 常にすべての情報を表示する必要がない――式を含むセルを編集するときだけ、式が見えればよい。その他の場合は、値が見えればよい。
表計算はフラストレーションのたまるツールでもあります。 構造がないのは実験でもありますが、普通はもっと構造的なほうが扱いやすいものです。
ですから、言語ワークベンチでのDSLを考えるときは、 ここで示したような言語(それとモデラーによって開発されたグラフィカル言語)は考えないようにしたほうがいいと思います。 それよりも、次世代の表計算ソフトのようなものを考える方がよいでしょう。
結論
この記事は言語ワークベンチを紹介することを目的に書きました。 マネージャからプログラミング環境をすべて言語ワークベンチに取り替えるように言われても、ちゃんと仕事を成し遂げられるよう、十分に理解して欲しいと思います。
私の考えでは、言語ワークベンチには主に2つの利点があります。 ひとつは、より良いツールによりプログラマの生産性が高められること。 もうひとつは、ドメイン専門家と密に連携することで、開発効率が高められることです。 これは開発の基礎となるものにドメイン専門家が貢献できる機会を与えることで実現できます。 これらの利点が本当に実現できるかどうかは、時間が経てば分かります。 ただ、この2つの利点があれば確かに生産性は向上されますが、そのインパクトはそれほど大きくはないでしょう。 言語ワークベンチが開発とドメイン専門家との関係に多大なる影響を与えれば、すさまじい効果が出ると思います――ただし、成功のためにはCOBOL推論を克服する必要があります。
私が気付いたなかで最も興味深かったことは、みんな言語ワークベンチを実際に体験するまでDSLがどんなものかまったく分からないということです。 今のところ私も、テキスト言語やグラフィカル言語の固定観念に囚われています。 今後は、エディタやスキーマとの相互作用により、みんなが思う「外部DSL」とは全く異なるものが出てくる可能性があります。 言語ワークベンチがそういった全く新しい代物になれば、「DSLはこうあるべき」と今考えていることを10年後に振り返って、思わず笑ってしまうことでしょう。
私が示したように、言語ワークベンチはまだ開発の初期段階にあります。 実践投入できるようになるには、数年はかかると思います。 言語ワークベンチがソフトウェア開発の代表的なものになるかどうかは、支持者はそう願っているでしょうが、私には分かりません。 私は別に技術未来派ではありません。 言語ワークベンチは我々のビジョンの端にある興味深い考え方のうちの1つでしかありません。 言語ワークベンチがその可能性を実現すれば、我々の専門分野に多大なる影響を与えるでしょう。 たとえ実現できなくとも、何か面白いアイデアをもたらしてくれると思います。
ですから、この分野には注目しておくとよいでしょう。 面白い分野ですし、飽きのこない寿命の長い分野でもあります。 幸運にもここ数ヶ月間、私はこの分野についての見識を手に入れました。 今後もしばらくは、関心を持ちつづけるつもりです。
’'’さらに詳しく読むために’’’
さらに詳しく読むための参考文献をblikiに書きました。 更新した個所を報告しやすいからです。
’'’謝辞’’’
ThoughtWorksの同僚Matt Foemmelには最大の感謝を。Mattはツール作りの要となる人物で、我々の開発業務をスピードアップさせる方法を常に探しています。 彼は2004年の初めにIntentional Programmingに興味を持ち始めました。 彼の調査からは、多大なる恩恵を受けました。 今年、彼はIntentional Softwareでの開発に取り組んだのですが、 その経験は私の理解に非常に役立ちました。
敬愛するあるソフトウェア ツール会社がこの分野に進出していることを聞いたとき、すぐに興味を持ちました。 Sergey Dmitrievはボストンの私のオフィスから数マイルのところにいたので、なおさら都合が良かったのです。 Sergeyは開発中のMPSを何度も紹介してくれました。 彼のチームがAgreementの例をMPSで実装してくれたおかげで、 ベイパーウェアではない動く例を紹介することができました。 Igor Alshannikovは、避けられないソフトウェアの問題に遭遇していたときに助けてくれました。それはまだ開発途中の段階でした。
ここ数年間、Intentional Softwareは非常に静かに自分達のアイデアを発展させてきました。 Charles Simonyiは私にツールや計画を紹介してくれました。 Magnus Christersonとまた一緒に協力することができました。 彼は今もIntentional Softwareに在籍しています。
80年代、90年代に英国にいた多くのひとと同様に、私もOOコミュニティのリーダーであるSteve Cookから多大なる恩恵を授かりました。 そのとき以来、彼はUMLの茂みのような仕様について助けてくれたり、 この記事では、MicrosfotのSoftware Factories initiativeに関する情報を提供してくれました。 このプロジェクトで多くの友人(Keith Short、Jack Greenfield、Alan Wills、Stuart Kent)に出会えたことも助けになりました。 彼らからは、多くの情報を提供してもらいました。
Daniel Jackson教授のおかげで何度かMITに訪問することができ、非常に楽しい経験でした。教授からはJonathon Edwardsを紹介してもらいました。 最初見たときは劇的な考えを理解できませんでしたが、ようやく理解することができました。
ThoughtWorksにいて最高なのは、面白いことをやっている才能ある人間にすぐにアクセスできることです。 今回だと、Intentionalツールをよく使っている人間(Matt Foemmel、Jeremy Stell-Smith、Jason Wadsworth)にアクセスできたことが非常に役に立ちました。
ThoughtWorksの同僚について言えば、Rebecca ParsonsやDave Riceは性能のよい知的サウンドボードを持っており、私の考えがブレないようにするためには欠かせませんでした。
Rebecca Parsons、Dave ‘Bedarra’ Thomas、Steve Cook、Jack Greenfield、Bill Caputo、 Obie Fernandez、Magnus Christerson、Igor Alshannikovからは、この記事を書くための背景情報の提供と、ドラフトのレビューを行ってもらいました。
Dave HooverとRavi Mohanは誤植を見つけてくれました。
更新履歴
- 2005/6/12:初出
翻訳について
- 翻訳:kdmsnr
-
訳注:コメント行は0から始まっているから分かりにくいです。 ↩